
003-三、GC 性能优化 – Java中的垃圾收集
除了对作者表示感谢外,还需要感谢译者【铁锚】,谢谢两位的付出
出处:https://blog.csdn.net/renfufei/column/info/14851
标记-清除(Mark and Sweep)是最经典的垃圾收集算法。将理论用于生产实践时, 会有很多需要优化调整的地点, 以适应具体环境。下面通过一个简单的例子, 让我们一步步记录下来, 看看如何才能保证 JVM 能安全持续地分配对象。
碎片整理(Fragmenting and Compacting)
每次执行清除(sweeping), JVM 都必须保证不可达对象占用的内存能被回收重用。但这(最终)有可能会产生内存碎片(类似于磁盘碎片), 进而引发两个问题:
- 写入操作越来越耗时, 因为寻找一块足够大的空闲内存会变得非常麻烦。
- 在创建新对象时,
JVM在连续的块中分配内存。如果碎片问题很严重, 直至没有空闲片段能存放下新创建的对象,就会发生内存分配错误(allocationerror)。
要避免这类问题,JVM必须确保碎片问题不失控。因此在垃圾收集过程中, 不仅仅是标记和清除, 还需要执行 “内存碎片整理” 过程。这个过程让所有可达对象(reachableobjects)依次排列, 以消除(或减少)碎片。示意图如下所示:
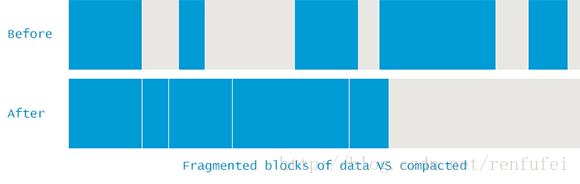

说明:JVM中的引用是一个抽象的概念,如果GC移动某个对象, 就会修改(栈和堆中)所有指向该对象的引用。
移动/提升/压缩 是一个 STW 的过程,所以修改对象引用是一个安全的行为。
分代假设(Generational Hypothesis)
我们前面提到过,执行垃圾收集需要停止整个应用。很明显,对象越多则收集所有垃圾消耗的时间就越长。但可不可以只处理一个较小的内存区域呢? 为了探究这种可能性,研究人员发现,程序中的大多数可回收的内存可归为两类:
- 大部分对象很快就不再使用
- 还有一部分不会立即无用,但也不会持续(太)长时间
这些观测形成了 弱代假设(WeakGenerationalHypothesis)。基于这一假设, VM中的内存被分为年轻代(YoungGeneration)和老年代(OldGeneration)。老年代有时候也称为 年老区(Tenured)。

拆分为这样两个可清理的单独区域,允许采用不同的算法来大幅提高GC的性能。
这种方法也不是没有问题。例如,在不同分代中的对象可能会互相引用, 在收集某一个分代时就会成为 “事实上的” GC root。
当然,要着重强调的是,分代假设并不适用于所有程序。因为GC算法专门针对“要么死得快”,“否则活得长” 这类特征的对象来进行优化, JVM 对收集那种存活时间半长不长的对象就显得非常尴尬了。
内存池(Memory Pools)
堆内存中的内存池划分也是类似的。不太容易理解的地方在于各个内存池中的垃圾收集是如何运行的。请注意,不同的GC算法在实现细节上可能会有所不同,但和本章所介绍的相关概念都是一致的。

新生代(Eden,伊甸园)
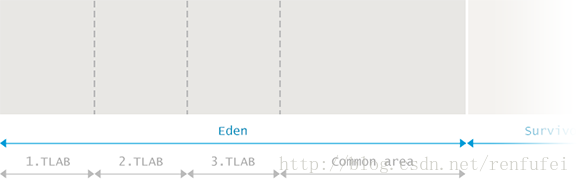
Eden 是内存中的一个区域, 用来分配新创建的对象。通常会有多个线程同时创建多个对象, 所以 Eden 区被划分为多个 线程本地分配缓冲区(Thread Local Allocation Buffer, 简称TLAB)。通过这种缓冲区划分,大部分对象直接由 JVM 在对应线程的TLAB中分配, 避免与其他线程的同步操作。
如果 TLAB 中没有足够的内存空间, 就会在共享 Eden 区(shared Eden space)之中分配。如果共享 Eden 区也没有足够的空间, 就会触发一次 年轻代 GC 来释放内存空间。如果 GC 之后 Eden 区依然没有足够的空闲内存区域, 则对象就会被分配到老年代空间(Old Generation)。
当 Eden 区进行垃圾收集时, GC 将所有从 root 可达的对象过一遍, 并标记为存活对象。
我们曾指出,对象间可能会有跨代的引用, 所以需要一种方法来标记从其他分代中指向 Eden 的所有引用。这样做又会遭遇各个分代之间一遍又一遍的引用。JVM 在实现时采用了一些绝招: 卡片标记(card-marking)。从本质上讲,JVM 只需要记住 Eden 区中 “脏”对象的粗略位置, 可能有老年代的对象引用指向这部分区间。更多细节请参考: Nitsan 的博客 。
标记阶段完成后, Eden中所有存活的对象都会被复制到存活区(Survivor spaces)里面。整个Eden区就可以被认为是空的, 然后就能用来分配新对象。这种方法称为 “标记-复制”(Mark and Copy): 存活的对象被标记, 然后复制到一个存活区(注意,是复制,而不是移动)。
存活区(Survivor Spaces)
Eden 区的旁边是两个存活区, 称为 from 空间和 to 空间。需要着重强调的的是, 任意时刻总有一个存活区是空的(empty)。
空的那个存活区用于在下一次年轻代 GC 时存放收集的对象。年轻代中所有的存活对象(包括 Edenq 区和非空的那个 “from” 存活区)都会被复制到 ”to“ 存活区。GC 过程完成后, ”to“ 区有对象,而 ‘from’ 区里没有对象。两者的角色进行正好切换 。
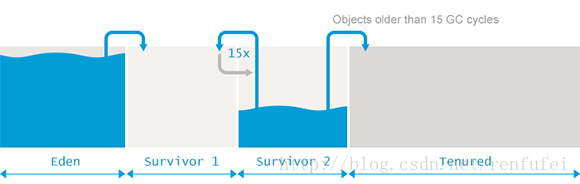
存活的对象会在两个存活区之间复制多次, 直到某些对象的存活 时间达到一定的阀值。分代理论假设, 存活超过一定时间的对象很可能会继续存活更长时间。
这类“ 年老” 的对象因此被提升(promoted )到老年代。提升的时候, 存活区的对象不再是复制到另一个存活区,而是迁移到老年代, 并在老年代一直驻留, 直到变为不可达对象。
为了确定一个对象是否“足够老”, 可以被提升(Promotion)到老年代,GC模块跟踪记录每个存活区对象存活的次数。每次分代GC完成后,存活对象的年龄就会增长。当年龄超过提升阈值(tenuring threshold), 就会被提升到老年代区域。
具体的提升阈值由JVM动态调整,但也可以用参数-XX:+MaxTenuringThreshold 来指定上限。如果设置 -XX:+MaxTenuringThreshold=0, 则GC时存活对象不在存活区之间复制,直接提升到老年代。现代 JVM 中这个阈值默认设置为15个 GC 周期。这也是HotSpot中的最大值。
如果存活区空间不够存放年轻代中的存活对象,提升(Promotion)也可能更早地进行。
老年代(Old Generation)
老年代的GC实现要复杂得多。老年代内存空间通常会更大,里面的对象是垃圾的概率也更小。
老年代GC发生的频率比年轻代小很多。同时, 因为预期老年代中的对象大部分是存活的, 所以不再使用标记和复制(Mark and Copy)算法。而是采用移动对象的方式来实现最小化内存碎片。老年代空间的清理算法通常是建立在不同的基础上的。原则上,会执行以下这些步骤:
- 通过标志位(
markedbit),标记所有通过GC roots可达的对象. - 删除所有不可达对象
- 整理老年代空间中的内容,方法是将所有的存活对象复制,从老年代空间开始的地方,依次存放。
通过上面的描述可知, 老年代GC必须明确地进行整理,以避免内存碎片过多。
永久代(PermGen)
在Java 8 之前有一个特殊的空间,称为“永久代”(Permanent Generation)。这是存储元数据(metadata)的地方,比如 class 信息等。
此外,这个区域中也保存有其他的数据和信息, 包括 内部化的字符串(internalized strings)等等。实际上这给Java开发者造成了很多麻烦,因为很难去计算这块区域到底需要占用多少内存空间。
预测失败导致的结果就是产生 java.lang.OutOfMemoryError: Permgen space 这种形式的错误。除非 ·OutOfMemoryError· 确实是内存泄漏导致的,否则就只能增加 permgen 的大小,例如下面的示例,就是设置 permgen 最大空间为 256 MB:
java -XX:MaxPermSize=256m com.mycompany.MyApplication
元数据区(Metaspace)
既然估算元数据所需空间那么复杂, Java 8直接删除了永久代(Permanent Generation),改用 Metaspace。从此以后, Java 中很多杂七杂八的东西都放置到普通的堆内存里。
当然,像类定义(class definitions)之类的信息会被加载到 Metaspace 中。元数据区位于本地内存(native memory),不再影响到普通的 Java 对象。默认情况下, Metaspace 的大小只受限于 Java进程可用的本地内存。这样程序就不再因为多加载了几个类/JAR包就导致 java.lang.OutOfMemoryError: Permgen space. 。注意, 这种不受限制的空间也不是没有代价的 —— 如果 Metaspace 失控, 则可能会导致很严重的内存交换(swapping), 或者导致本地内存分配失败。
如果需要避免这种最坏情况,那么可以通过下面这样的方式来限制 Metaspace 的大小, 如 256 MB:
java -XX:MaxMetaspaceSize=256m com.mycompany.MyApplication
Minor GC vs Major GC vs Full GC
垃圾收集事件(Garbage Collection events)通常分为: 小型GC(Minor GC) – 大型GC(Major GC) – 和完全GC(Full GC) 。本节介绍这些事件及其区别。然后你会发现这些区别也不是特别清晰。
最重要的是,应用程序是否满足 服务级别协议(Service Level Agreement, SLA), 并通过监控程序查看响应延迟和吞吐量。也只有那时候才能看到GC事件相关的结果。重要的是这些事件是否停止整个程序,以及持续多长时间。
虽然 Minor, Major 和 Full GC 这些术语被广泛应用, 但并没有标准的定义, 我们还是来深入了解一下具体的细节吧。
小型GC(Minor GC)
年轻代内存的垃圾收集事件称为小型 GC。这个定义既清晰又得到广泛共识。对于小型 GC 事件,有一些有趣的事情你应该了解一下:
1、当JVM无法为新对象分配内存空间时总会触发 Minor GC,比如 Eden 区占满时。所以(新对象)分配频率越高, Minor GC 的频率就越高。
2、Minor GC 事件实际上忽略了老年代。从老年代指向年轻代的引用都被认为是 GC Root。而从年轻代指向老年代的引用在标记阶段全部被忽略。
3、与一般的认识相反, Minor GC 每次都会引起全线停顿(stop-the-world ), 暂停所有的应用线程。对大多数程序而言,暂停时长基本上是可以忽略不计的, 因为 Eden 区的对象基本上都是垃圾, 也不怎么复制到存活区/老年代。如果情况不是这样, 大部分新创建的对象不能被垃圾回收清理掉, 则 Minor GC 的停顿就会持续更长的时间。
所以 Minor GC 的定义很简单 —— Minor GC 清理的就是年轻代。
Major GC vs Full GC
值得一提的是, 这些术语并没有正式的定义 —— 无论是在JVM规范还是在GC相关论文中。
我们知道, Minor GC 清理的是年轻代空间(Young space),相应的,其他定义也很简单:
Major GC(大型GC) 清理的是老年代空间(Oldspace)。FullGC(完全GC)清理的是整个堆, 包括年轻代和老年代空间。
杯具的是更复杂的情况出现了。很多 Major GC 是由 Minor GC 触发的, 所以很多情况下这两者是不可分离的。另一方面, 像G1这样的垃圾收集算法执行的是部分区域垃圾回收, 所以,额,使用术语“cleaning”并不是非常准确。
这也让我们认识到,不应该去操心是叫 Major GC 呢还是叫 Full GC, 我们应该关注的是: 某次GC事件 是否停止所有线程,或者是与其他线程并发执行。
这些混淆甚至根植于标准的JVM工具中。我的意思可以通过实例来说明。让我们来对比同一JVM中两款工具的GC信息输出吧。这个JVM使用的是 并发标记和清除收集器(Concurrent Mark and Sweep collector,-XX:+UseConcMarkSweepGC).
首先我们来看 jstat 的输出:
jstat -gc -t 4235 1s
Time S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
5.7 34048.0 34048.0 0.0 34048.0 272640.0 194699.7 1756416.0 181419.9 18304.0 17865.1 2688.0 2497.6 3 0.275 0 0.000 0.275
6.7 34048.0 34048.0 34048.0 0.0 272640.0 247555.4 1756416.0 263447.9 18816.0 18123.3 2688.0 2523.1 4 0.359 0 0.000 0.359
7.7 34048.0 34048.0 0.0 34048.0 272640.0 257729.3 1756416.0 345109.8 19072.0 18396.6 2688.0 2550.3 5 0.451 0 0.000 0.451
8.7 34048.0 34048.0 34048.0 34048.0 272640.0 272640.0 1756416.0 444982.5 19456.0 18681.3 2816.0 2575.8 7 0.550 0 0.000 0.550
9.7 34048.0 34048.0 34046.7 0.0 272640.0 16777.0 1756416.0 587906.3 20096.0 19235.1 2944.0 2631.8 8 0.720 0 0.000 0.720
.7 34048.0 34048.0 0.0 34046.2 272640.0 80171.6 1756416.0 664913.4 20352.0 19495.9 2944.0 2657.4 9 0.810 0 0.000 0.810
.7 34048.0 34048.0 34048.0 0.0 272640.0 129480.8 1756416.0 745100.2 20608.0 19704.5 2944.0 2678.4 10 0.896 0 0.000 0.896
.7 34048.0 34048.0 0.0 34046.6 272640.0 164070.7 1756416.0 822073.7 20992.0 19937.1 3072.0 2702.8 11 0.978 0 0.000 0.978
.7 34048.0 34048.0 34048.0 0.0 272640.0 211949.9 1756416.0 897364.4 21248.0 20179.6 3072.0 2728.1 12 1.087 1 0.004 1.091
.7 34048.0 34048.0 0.0 34047.1 272640.0 245801.5 1756416.0 597362.6 21504.0 20390.6 3072.0 2750.3 13 1.183 2 0.050 1.233
.7 34048.0 34048.0 0.0 34048.0 272640.0 21474.1 1756416.0 757347.0 22012.0 20792.0 3200.0 2791.0 15 1.336 2 0.050 1.386
.7 34048.0 34048.0 34047.0 0.0 272640.0 48378.0 1756416.0 838594.4 22268.0 21003.5 3200.0 2813.2 16 1.433 2 0.050 1.484
此片段截取自JVM启动后的前17秒。根据这些信息可以得知: 有2次Full ``GC在12次Minor GC(YGC)之后触发执行, 总计耗时 50ms。当然,也可以通过具备图形界面的工具得出同样的信息, 比如 jconsole 或者 jvisualvm (或者最新的 jmc)。
在下结论之前, 让我们看看此JVM进程的GC日志。显然需要配置 -XX:+PrintGCDetails 参数,GC日志的内容更详细,结果也有一些不同:
java -XX:+PrintGCDetails -XX:+UseConcMarkSweepGC eu.plumbr.demo.GarbageProducer
.157: [GC (Allocation Failure) 3.157: [ParNew: 272640K->34048K(306688K), 0.0844702 secs] 272640K->69574K(2063104K), 0.0845560 secs] [Times: user=0.23 sys=0.03, real=0.09 secs]
.092: [GC (Allocation Failure) 4.092: [ParNew: 306688K->34048K(306688K), 0.1013723 secs] 342214K->136584K(2063104K), 0.1014307 secs] [Times: user=0.25 sys=0.05, real=0.10 secs]
... cut for brevity ...
.292: [GC (Allocation Failure) 11.292: [ParNew: 306686K->34048K(306688K), 0.0857219 secs] 971599K->779148K(2063104K), 0.0857875 secs] [Times: user=0.26 sys=0.04, real=0.09 secs]
.140: [GC (Allocation Failure) 12.140: [ParNew: 306688K->34046K(306688K), 0.0821774 secs] 1051788K->856120K(2063104K), 0.0822400 secs] [Times: user=0.25 sys=0.03, real=0.08 secs]
.989: [GC (Allocation Failure) 12.989: [ParNew: 306686K->34048K(306688K), 0.1086667 secs] 1128760K->931412K(2063104K), 0.1087416 secs] [Times: user=0.24 sys=0.04, real=0.11 secs]
.098: [GC (CMS Initial Mark) [1 CMS-initial-mark: 897364K(1756416K)] 936667K(2063104K), 0.0041705 secs] [Times: user=0.02 sys=0.00, real=0.00 secs]
.102: [CMS-concurrent-mark-start]
.341: [CMS-concurrent-mark: 0.238/0.238 secs] [Times: user=0.36 sys=0.01, real=0.24 secs]
.341: [CMS-concurrent-preclean-start]
.350: [CMS-concurrent-preclean: 0.009/0.009 secs] [Times: user=0.03 sys=0.00, real=0.01 secs]
.350: [CMS-concurrent-abortable-preclean-start]
.878: [GC (Allocation Failure) 13.878: [ParNew: 306688K->34047K(306688K), 0.0960456 secs] 1204052K->1010638K(2063104K), 0.0961542 secs] [Times: user=0.29 sys=0.04, real=0.09 secs]
.366: [CMS-concurrent-abortable-preclean: 0.917/1.016 secs] [Times: user=2.22 sys=0.07, real=1.01 secs]
.366: [GC (CMS Final Remark) [YG occupancy: 182593 K (306688 K)]14.366: [Rescan (parallel) , 0.0291598 secs]14.395: [weak refs processing, 0.0000232 secs]14.395: [class unloading, 0.0117661 secs]14.407: [scrub symbol table, 0.0015323 secs]14.409: [scrub string table, 0.0003221 secs][1 CMS-remark: 976591K(1756416K)] 1159184K(2063104K), 0.0462010 secs] [Times: user=0.14 sys=0.00, real=0.05 secs]
.412: [CMS-concurrent-sweep-start]
.633: [CMS-concurrent-sweep: 0.221/0.221 secs] [Times: user=0.37 sys=0.00, real=0.22 secs]
.633: [CMS-concurrent-reset-start]
.636: [CMS-concurrent-reset: 0.002/0.002 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
通过 GC 日志可以看到, 在 12 次 Minor GC 之后发生了一些 “不同的事情”。并不是两个 Full GC, 而是在老年代执行了一次 GC, 分为多个阶段执行:
- 初始标记阶段(
InitialMarkphase),耗时0.0041705秒(约4ms)。此阶段是全线停顿(STW)事件,暂停所有应用线程,以便执行初始标记。 - 标记和预清理阶段(
MarkupandPrecleanphase)。和应用线程并发执行。 - 最终标记阶段(
FinalRemarkphase), 耗时0.0462010秒(约46ms)。此阶段也是全线停顿(STW)事件。 - 清除操作(
Sweep)是并发执行的, 不需要暂停应用线程。
所以从实际的GC日志可以看到, 并不是执行了两次FullGC操作, 而是只执行了一次清理老年代空间的MajorGC。
如果只关心延迟, 通过后面 jstat 显示的数据, 也能得出正确的结果。它正确地列出了两次 STW 事件,总计耗时 50 ms。这段时间影响了所有应用线程的延迟。如果想要优化吞吐量, 这个结果就会有误导性 —— jstat 只列出了 stop-the-world 的初始标记阶段和最终标记阶段, jstat 的输出完全隐藏了并发执行的GC阶段。
写完了如果写得有什么问题,希望读者能够给小编留言,也可以点击[此处扫下面二维码关注微信公众号](https://www.ycbbs.vip/?p=28 "此处扫下面二维码关注微信公众号")
看完两件小事
如果你觉得这篇文章对你挺有启发,我想请你帮我两个小忙:
- 把这篇文章分享给你的朋友 / 交流群,让更多的人看到,一起进步,一起成长!
- 关注公众号 「方志朋」,公众号后台回复「666」 免费领取我精心整理的进阶资源教程

本文著作权归作者所有,如若转载,请注明出处
转载请注明:文章转载自「 Java极客技术学习 」https://www.javajike.com
 微信扫一扫
微信扫一扫