
某618大促项目的复盘总结
一、前言
618期间上线一个活动项目。但上线不顺利,当天就出现了性能问题,接口超时,用户无法打开网页,最后不得的临时下线。花了三天两夜,重构了后台核心代码,才让活动进行下去。
回头看了一下自己的时间记录,从5月31号那天晚上8点25分开始准备上线,发现异常,分析原因,重构代码,离开公司时已经是6月2号的23点54,经历51小时29分,中间的睡眠时间不到5个小时,这已经是爆发小宇宙了。
这一波刚过去了,一波未平另一波又起,由于活动的奖励丰厚,大批羊毛党闻风而至,某宝上公开卖脚本的都有了,严重影响了正常用户薅羊毛。
某客户反馈说:我们别说薅羊毛了,现在是整头羊都被他们牵走了!
接下来的几天,又得和薅羊毛的脚本们斗智斗勇,直到活动结束。
而本文就对此做一次深度的复盘,在以后的项目中让自己快活一点。
二、一份看似完美的项目总结
当我们复盘项目过程时,能找到很多问题点,比如:
- 人力不足,需求过于复杂,开发和测试工作量大。
- 前后端开发、测试都是从其他团队抽掉的,对当前项目的业务和技术不熟悉。
- 跨团队组建的临时团队,职责定义不清晰,项目管控不严格。
- 开发对项目的用到的技术不熟悉,没有经过原有项目成员的CodeReview。
- 测试通过太草率,压测方案设计不合理。
….
列出问题后,很快就能一一写出改进点。
- 从公司层面加强的整体项目安排,避免重复玩法的项目,资源投入到重点的几个活动中。
- 加强团队的能力培养,总结文档,供新人学习。
- 对于核心代码进行CodeReview,遇到问题时,项目经理协调资深开发协助解决。
- 将临时组建团队职责定义清晰,各负责人沟通清楚。
- 严格控制测试质量,测试有上线的否决权。
…
这些总结看起来一点问题没有,列出了问题,也列出了改进点,甚至可以当成样板去使用了,是不是咱们就这么结束了呢。
当然不是, 它本身的说法没有错,错在把问题的前提当作问题的原因。
我们来看两种表述。
- 下次我们要组建一个经验丰富的项目团队,避免质量问题发生。
- 当下次我们面临一个临时组建,经验不足的项目团队时,如何避免质量问题发生。
这两种表述的差异在哪?
前一种表述是因为我们“团队”的原因,导致了本次质量问题,所以我们要解决“团队”的问题。
而后一种是我们的团队就是临时组建的,我们的开发、测试就是对新项目的业务和技术不熟悉,在这个前提下,才会出现质量问题,那么在这个前提下,怎么避免质量问题呢?
临时组建,经验不足不是问题的原因,它们是出现问题的前提,这是客观存在的。
这就好比我们说解决一个问题时,最快的方式是,我们不解决问题,解决出问题的人就行了。
在这里不就变成了,我们不解决问题,解决出问题的团队就行了。
正是因为这个误区,我们很多时候一出现项目质量问题,就把锅甩给我们团队的协作有问题,或者我们的项目时间紧张,然后一句下次改进就结束了。
这样的万能回答,看似一点没错,但往往就没法落地了。
明明项目时间紧,新团队协作经验不足本来就客观的存在,没有它就没有问题,怎么可以当作问题本身给解决掉呢。
1、质量问题的关键原因
带着这个前提,我们再回头看前面的总结,其实就能过滤出真正有价值的点了。
我们也可以这么问,问题是不能避免的,但为什么在项目过程中我们的性能问题没有暴露出来?
三个角度:
- 从项目角度,没有严格按项目流程来,特别是最后测试任务紧张,bug较多时,赶工给出了测试报告。
- 从开发角度,没有找熟悉业务和技术的同学做CodeReview。
- 从测试角度,压测方案设计不合理,不符合真实场景。
逐一分析下。
前面提到事故是后台的性能问题,从项目角度,就算流程严谨也没法暴露出性能问题,特别是在项目过程中,已暴露的风险是前端人力不足,中间加了人手,从功能的角度,后端进度完全正常。
再看开发角度,这里我没有提开发的经验不足,不是在推脱责任,这同我们作为一个临时团队对业务的经验不足一样,它是一个客观存在的前提。当你接触新项目,使用新技术时,经验不足是肯定存在的。
问题是在自身经验不足时,如何去完成任务,那么和熟悉业务和技术的同学做CodeReview是主要的手段。
再从测试角度,功能测试是没有问题的,但跟性能相关的压测方案是有问题的,并且一开始就没有引起正视。最开始的压测方案是开发只出接口和参数文档,直接丢给测试去压,现在看来,这是错误的。
因此,这次质量问题的关键总结如下。
当下次我们面临一个临时组建,经验不足的项目团队时,面对大流量的业务需求,开发们需要注意:
- 让熟悉业务和技术的同学帮忙做CodeReview。
- 设计出符合业务场景的压测方案。
这两点就可以落地了,这也不是说项目管理上没有改进的,而是优先保证这两点,能更有效的降低风险。
CodeReview的技巧这里就不多少说,来谈谈我们做的几次压测方案的改进。
2、三轮的压测改进
- 单用户,单接口,双机压测
- 随机用户,多接口,全量压测
- 随机用户,功能分组接口,全量压测
最开始压测方案是用一个用户,两台服务器,一个缓存分片做压测,然后简单的用服务器QPS的均值乘以线上部署机器数量当作压测结果。
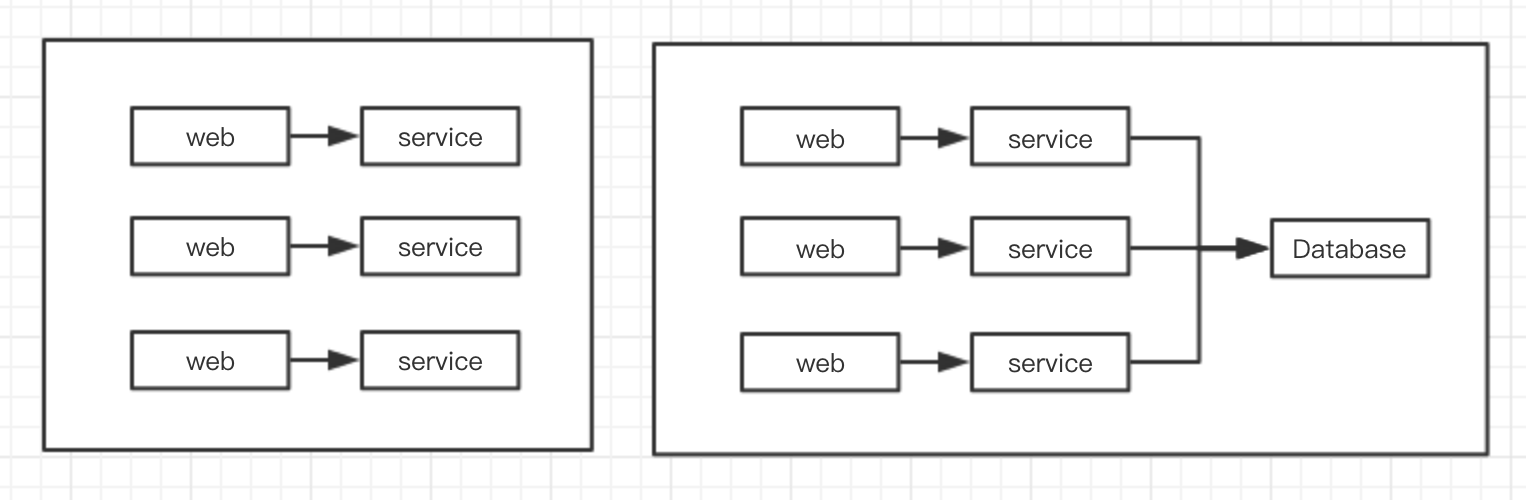
这个方案如果是下图左侧的场景,调用链路上的服务器可以同时弹性扩展自然是可以的。
但要是右侧的场景,调用链路上存在瓶颈,比如数据库是一个节点,并且无法扩展,那就问题了。
同样的,这次项目的问题就是Redis成为了一个单节点的瓶颈。另外由于用户id是固定的,所以缓存很可能被重复使用,这样就难以测试到频繁创建缓存的场景。

在系统重构后,改进了一种压测方案,通过随机用户Id,批量轮询接口,并且通过测试环境的弹性扩展,完全模拟线上的部署环境。
还通过加降级开关,把入参合法性、风控、时效性校验等临时关闭,以便能让压测的请求贯穿整个主流程。
接着在这一方案的基础上,通过对接口分组和伪造恰当的数据,编写贴近真实的调用行为的脚本,再次做了压测。
在执行人员上,也经历了从开发提供数据,测试全权负责;到测试主导,开发参与;再到开发主导,测试协助的过程。
由此,压测方案就越来越贴近真实场景,压测结论自然就更加可信 。
3、高并发场景下的设计
前面谈到了系统设计的不合理导致了本次性能问题,来分析下这里面的根本原因。
首先要理解的是,Redis集群是由多个分片构成的,一条数据被写到哪个分片里,是由key的hash值来离散的。
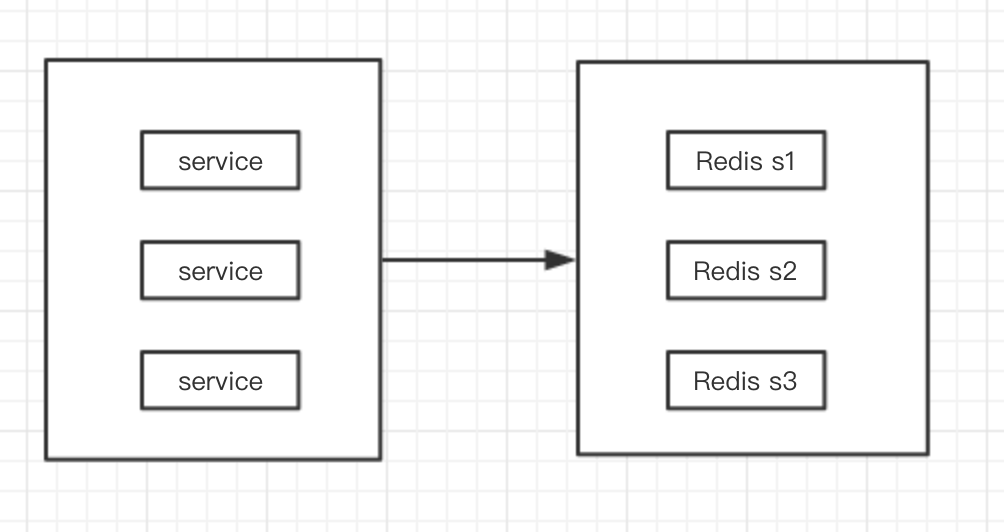
比如说,我们要在Redis里面缓存一批用户信息,并且能通过ID来存取。
如果用Redis自带的Hash表结构写法如下:
存:redis.hset("userMap",ID,userInfo)
读:redis.hget("userMap",ID)
那么,因为key是固定的userMap,这意味着所有的用户信息都会被写到一个分片里。
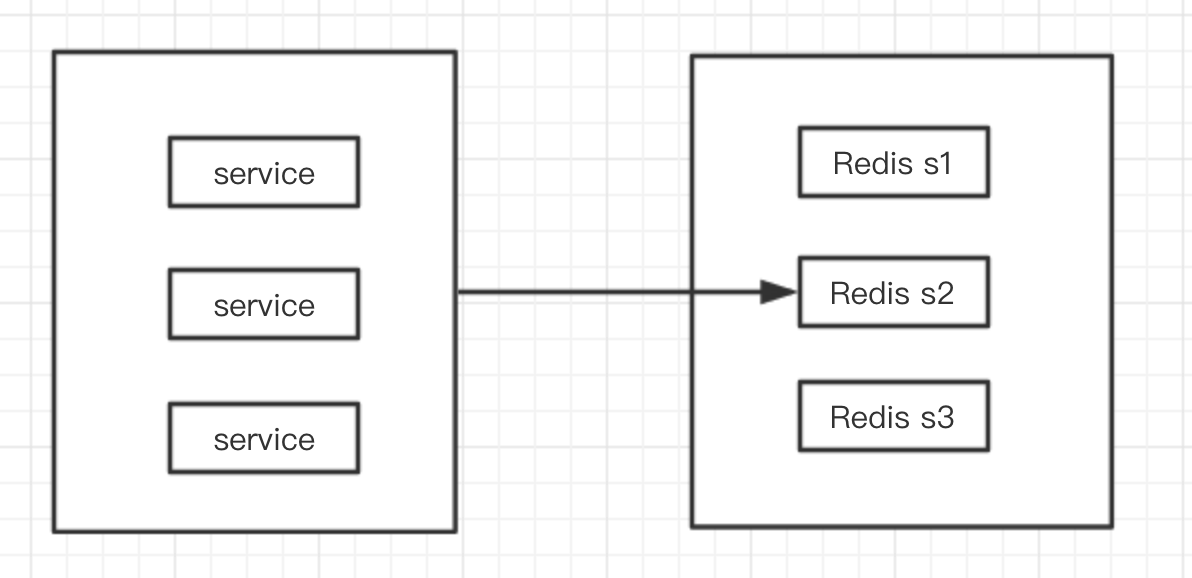
而对于通常的分布式系统的设计,一个基本原则是:让流量尽可能的被集群的机器平摊。
固定的key就无法利用分布式的优势了,并且如果并发量高,这就会让一个分片去抗所有的流量,再加上如果用户量数十万,还有一次性读取所有数据的操作,这样就变成一场灾难了。
实际设计时,直接把整个Redis集群当作一个Hash表的方式更加高效。
存:redis.set("userMap"+ID,userInfo)
读:redis.get("userMap"+ID)
这里的key="userMap"+ID,ID不同key就被离散了,请求会集群平摊,从而充分发挥分布式系统的性能。
三、黑产和羊毛党的问题
在项目上线后另一个没重视的问题出现了,那就是大量的黑产和羊毛党出现,活动奖励全被这些用脚本的人占据了。
对黑产的事前考虑太少了,仅做了简单的风控校验,根本检测不足异常用户,导致黑产可以通过脚本大量刷接口。
这里的经验有两点:
- 对包含现金、现金等价物或高价值奖励的活动,要有面对黑产的心理预期。
- 在大公司,专业的事情找专业的人做,基于业务场景,提前跟风控团队沟通好。
对于第一点,基本上只要值点钱的活动,黑产肯定跑不了,空手套白狼,抢到就是赚到,不妨想想如果你是黑产,结合下业务场景,你会怎么来刷自己的系统。
基于第一点,公司没有风控团队那就只能自己做了,而一般上点规模的公司都有自己的风控团队,利用好现成资源。
风控主要考虑两方面:
- 有风控团队的,接入他们的通用风控模型。
- 针对项目的业务场景,定制化一些风控模型。
通用风控模型基本是通过新老账号、异地登录、人机识别等等用户行为建立的用户画像,通过离线计算和实时校验来处理。
定制化模型视情况而定,比如拉一个单独的小黑户,放进去的用户不能参与这个活动等等。
被拦截的用户一般是走验证码或直接拉黑,对于后者,别忘了和客服的妹子们打好招呼,准备下话术应对客诉。
四、结语
最后总结下项目的经验。
首先是前提:
- 当你的面前的是一个临时组建,对现在项目经验不足的项目团队时。
- 当你面临一个大流量,包含现金或等价物的活动时。
请务必做好这三点:
- 找熟悉本项目的业务和技术的开发参与方案的设计和CodeReview。
- 请开发主动参与压测任务,设计压测方案,注意尽可能模拟真实场景。
- 做好应对黑产的心理准备,直到大促活动结束。
来自于,一个连续加班51小时29分,被用户吐槽整只羊都被人家牵走了的开发。
作者:wchukai
来源:https://www.cnblogs.com/wchukai/p/11174189.html
看完两件小事
如果你觉得这篇文章对你挺有启发,我想请你帮我两个小忙:
- 把这篇文章分享给你的朋友 / 交流群,让更多的人看到,一起进步,一起成长!
- 关注公众号 「方志朋」,公众号后台回复「666」 免费领取我精心整理的进阶资源教程

本文著作权归作者所有,如若转载,请注明出处
转载请注明:文章转载自「 Java极客技术学习 」https://www.javajike.com
 微信扫一扫
微信扫一扫