
042-四十二、Java集合框架详解
Java 集合框架
早在Java 2中之前,Java就提供了特设类。比如:Dictionary, Vector, Stack, 和 Properties 这些类用来存储和操作对象组。
虽然这些类都非常有用,但是它们缺少一个核心的,统一的主题。由于这个原因,使用 Vector 类的方式和使用 Properties 类的方式有着很大不同。
集合框架被设计成要满足以下几个目标:
该框架必须是高性能的。基本集合(动态数组,链表,树,哈希表)的实现也必须是高效的。
该框架允许不同类型的集合,以类似的方式工作,具有高度的互操作性。
对一个集合的扩展和适应必须是简单的。
为此,整个集合框架就围绕一组标准接口而设计。你可以直接使用这些接口的标准实现,诸如: LinkedList, HashSet, 和 TreeSet等,除此之外你也可以通过这些接口实现自己的集合。
集合框架是一个用来代表和操纵集合的统一架构。所有的集合框架都包含如下内容:
接口:是代表集合的抽象数据类型。接口允许集合独立操纵其代表的细节。在面向对象的语言,接口通常形成一个层次。
实现(类):是集合接口的具体实现。从本质上讲,它们是可重复使用的数据结构。
算法:是实现集合接口的对象里的方法执行的一些有用的计算,例如:搜索和排序。这些算法被称为多态,那是因为相同的方法可以在相似的接口上有着不同的实现。
除了集合,该框架也定义了几个Map接口和类。Map 里存储的是键/值对。尽管 Map 不是 collections,但是它们完全整合在集合中。
集合框架体系如图所示:
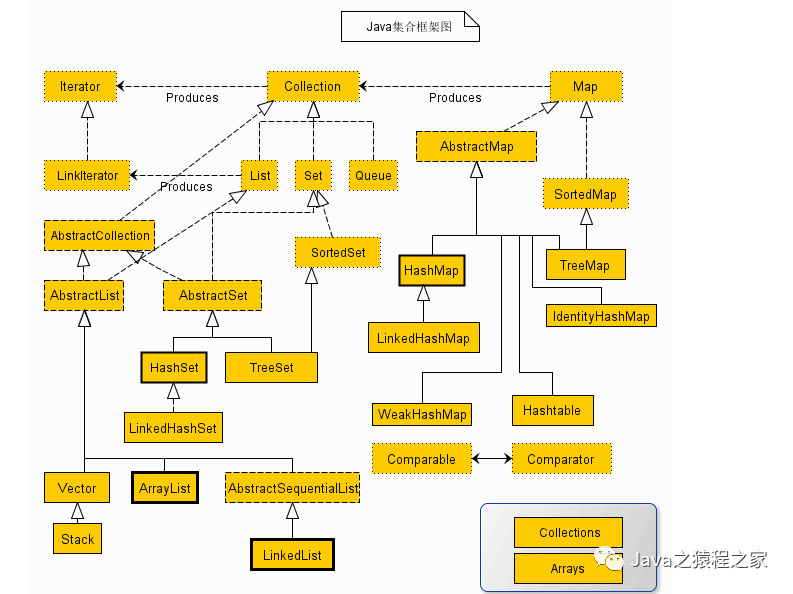

Java 集合框架提供了一套性能优良,使用方便的接口和类,java集合框架位于 java.util 包中, 所以当使用集合框架的时候需要进行导包。下面介绍几个接口中常用的接口以及实现类。
List接口的常用实现类
一个 List 是一个元素有序的、可以重复、可以为 null 的集合(有时候我们也叫它“序列”)。
ArrayList
最常用的List接口实现类,底层使用可变长度的动态数组实现。ArrayList有一个初始容量(capacity = 10),当元素数量大于初始容量时进行扩容,新的数组长度 = 旧数组长度 + 旧数组长度 / 2。
因为每个元素都有固定的位置索引,所以根据索引查询元素的速度非常快。如果在中间插入元素时,由于后面的元素全部要后移一位,所以性能会比较差。
由于没有做并发访问控制,所以它是一个非线程安全的集合。允许重复元素或null元素。
LinkedList
List 接口的双向链接的实现类,允许NULL元素。它表现上是一个有序的集合,但内存中其实是无序保存。
由于原因,所以它插入的速度会很快,但是查询一个元素的速度较 ArrayList 速度慢很多。是一个非线程安全的集合。
Vector
Vector 底层使用动态数组实现,默认初始容量为10,可以通过构造方法指定初始容量,同时可以指定扩容时的增量。
扩容规则是指 新容量 = 旧容量 + 扩容增量,若未指定扩容增量则 新容量 = 2 * 旧容量。它的关键方法都加了 synchronized,所以是一个线程安全的集合。
Set集合接口
如果是实现了 Set 接口的集合类,具备的特点:无序,不可重复
添加元素 的顺序与元素出来的顺序是不一致的。
注重独一无二的性质,该体系集合可以知道某物是否已近存在于集合中,不会存储重复的元素。
hashSet
HashSet 底层是使用了哈希表来支持的,特点: 存取速度快。
往Hashset添加元素的时候,HashSet会先调用元素的hashCode方法得到元素的哈希值 ,
然后通过元素的哈希值经过移位等运算,就可以算出该元素在哈希表中的存储位置。
LinkedHashSet
LinkedHashSet 底层使用 LinkedHashMap 来保存所有元素,它继承与 HashSet,其所有的方法操作上又与 HashSet 相同,因此 LinkedHashSet 的实现上非常简单,只提供了四个构造方法。
并通过传递一个标识参数,调用父类的构造器,底层构造一个 LinkedHashMap 来实现,在相关操作上与父类 HashSet 的操作相同,直接调用父类 HashSet 的方法即可。
treeSet
treeSet 底层是以红-黑树的数据结构实现的,默认对元素进行自然排序(String)。
如果在比较的时候两个对象返回值为0,那么元素重复。
Map接口的常用实现类
Map 提供了一个更通用的元素存储方法。 Map 集合类用于存储元素对(称作“键”和“值”),其中每个键映射到一个值。
从概念上而言,您可以将 List 看作是具有数值键的 Map。 而实际上,除了 List 和 Map 都在定义 java.util 中外,两者并没有直接的联系。
本文将着重介绍核心 Java 发行套件中附带的 Map,同时还将介绍如何采用或实现更适用于您应用程序特定数据的专用 Map。
HashMap
往 HashMap 添加元素的时候,首先会调用键的 hashCode 方法得到元素的哈希码值,然后经过运算 就可以算出该元素在哈希表中的存储位置。
并允许使用 null 值和 null 键。此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
HashTable
HashTable 是同步的(synchronized 函数),而 HashMap 不同步,所以 HashTable 要慢一些 HashTable 不接受 null 键和值。
而 HashMap 接受一个 null 键和无数个 null 值除了 keySet(), entrySet(),values() 这些 HashMap 支持的迭代之外,HashTable 还支持基于 Enumeration 的 keys(), elements(), 但是在现在它们的实现都是基于一个实现了 Enumeration 和 Iterator 接口的类。
TreeMap
TreeMap 也是基于红黑树(二叉树)数据结构实现 的, 特点:会对元素的键进行排序存储。
注意:Set的元素不可重复,如果set元素重复将添加不成功。
Map的键不可重复,如果键重复将直接覆盖。
写完了如果写得有什么问题,希望读者能够给小编留言,也可以点击[此处扫下面二维码关注微信公众号](https://www.ycbbs.vip/?p=28 "此处扫下面二维码关注微信公众号")
看完两件小事
如果你觉得这篇文章对你挺有启发,我想请你帮我两个小忙:
- 把这篇文章分享给你的朋友 / 交流群,让更多的人看到,一起进步,一起成长!
- 关注公众号 「方志朋」,公众号后台回复「666」 免费领取我精心整理的进阶资源教程

本文著作权归作者所有,如若转载,请注明出处
转载请注明:文章转载自「 Java极客技术学习 」https://www.javajike.com
 微信扫一扫
微信扫一扫