
10. kafka消费者如何分配分区
消费者如何分配分区就是指某个topic,其N个分区和消费该topic的若干消费者群组下M个消费者的关系。如下图所示,C0和C1两个消费者如何分配N个分区:
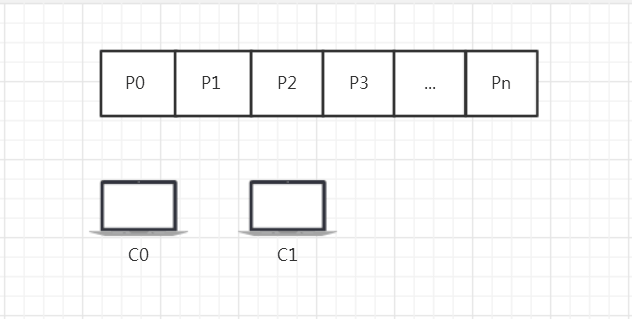

消费者&分区.png
- 核心接口:org.apache.kafka.clients.consumer.internals.PartitionAssignor
- 内置策略:org.apache.kafka.clients.consumer.RangeAssignor和org.apache.kafka.clients.consumer.RoundRobinAssignor。
- 默认策略:org.apache.kafka.clients.consumer.RangeAssignor
- 配置方式:在构造KafkaConsumer时增加参数partition.assignment.strategy,值为内置的两种策略中的一种,或者是一个实现了PartitionAssignor接口的全类名。例如:
... ...
// 指定分区分配策略
props.put("partition.assignment.strategy", "org.apache.kafka.clients.consumer.RangeAssignor");
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(props);
range策略
- 实现
org.apache.kafka.clients.consumer.RangeAssignor
- 说明
range策略针对于每个topic,各个topic之间分配时没有任何关联,分配步骤如下:
- topic下的所有有效分区平铺,例如P0, P1, P2, P3… …
- 消费者按照字典排序,例如C0, C1, C2
- 分区数除以消费者数,得到n
- 分区数对消费者数取余,得到m
- 消费者集合中,前m个消费者能够分配到n+1个分区,而剩余的消费者只能分配到n个分区。
所以对于某个topic来说:
如果有5个分区(P0, P1, P2, P3, P4),且订阅这个topic的消费者组有2个消费者(C0, C1)。那么P0, P1, P2将被C0消费,P3, P4将被C1消费。
如果有4个分区(P0, P1, P2, P3),且订阅这个topic的消费者组有2个消费者(C0, C1)。那么P0, P1将被C0消费,P2, P3将被C1消费。
range策略如下图所示:
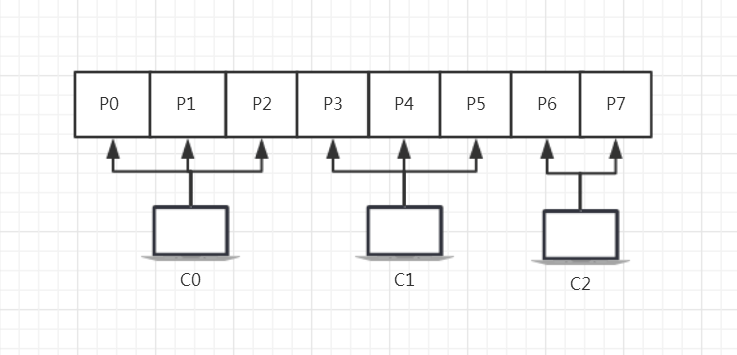
range策略
- 源码注释
The range assignor works on a per-topic basis. For each topic, we lay out the available partitions in numeric order and the consumers in lexicographic order. We then divide the number of partitions by the total number of consumers to determine the number of partitions to assign to each consumer. If it does not evenly divide, then the first few consumers will have one extra partition.
For example, suppose there are two consumers C0 and C1, two topics t0 and t1, and each topic has 3 partitions, resulting in partitions t0p0, t0p1, t0p2, t1p0, t1p1, and t1p2.
The assignment will be:
C0: [t0p0, t0p1, t1p0, t1p1]
C1: [t0p2, t1p2]
说明:两个topic分区数无法整除消费者数,所以,第一个消费者C0会多分配一个分区。所以C0消费p0和p1两个分区,C1消费p2分区。
- 源码
核心源码如下:
// partitionsPerTopic表示topic和分区关系,key是topic,value是分区数量
// subscriptions表示订阅关系,key是消费者,value是订阅的topic
@Override
public Map<String, List<TopicPartition>> assign(Map<String, Integer> partitionsPerTopic,
Map<String, Subscription> subscriptions) {
// 得到topic和订阅的消费者集合信息,例如{t0:[c0, c1], t1:[C0, C1]}
Map<String, List<String>> consumersPerTopic = consumersPerTopic(subscriptions);
// 保存topic分区和订阅该topic的消费者关系结果map
Map<String, List<TopicPartition>> assignment = new HashMap<>();
for (String memberId : subscriptions.keySet())
// memberId就是消费者client.id+uuid(kafka在client.id上追加的)
assignment.put(memberId, new ArrayList<TopicPartition>());
// 遍历每个topic和消费者集合信息组成的map(由这个遍历可知,range策略分配结果在各个topic之间互不影响)
for (Map.Entry<String, List<String>> topicEntry : consumersPerTopic.entrySet()) {
// topic名称
String topic = topicEntry.getKey();
// topic的消费者集合信息
List<String> consumersForTopic = topicEntry.getValue();
// 当前topic的分区数量
Integer numPartitionsForTopic = partitionsPerTopic.get(topic);
// 如果当天topic没有分区,那么继续遍历下一个topic
if (numPartitionsForTopic == null)
continue;
// 消费者集合根据字典排序
Collections.sort(consumersForTopic);
// 每个topic分区数量除以消费者数量,得出每个消费者分配到的分区数量
int numPartitionsPerConsumer = numPartitionsForTopic / consumersForTopic.size();
// 无法整除的剩余分区数量
int consumersWithExtraPartition = numPartitionsForTopic % consumersForTopic.size();
// 根据topic名称和分区数量,得到分区集合信息
List<TopicPartition> partitions = AbstractPartitionAssignor.partitions(topic, numPartitionsForTopic);
// 遍历订阅当前topic的消费者集合
for (int i = 0, n = consumersForTopic.size(); i < n; i++) {
// 分配到的分区的开始位置
int start = numPartitionsPerConsumer * i + Math.min(i, consumersWithExtraPartition);
// 分配到的分区数量(整除分配到的分区数量,加上1个无法整除分配到的分区--如果有资格分配到这个分区的话。判断是否有资格分配到这个分区:如果整除后余数为m,那么排序后的消费者集合中前m个消费者都能分配到一个额外的分区)
int length = numPartitionsPerConsumer + (i + 1 > consumersWithExtraPartition ? 0 : 1);
// 给消费者分配分区
assignment.get(consumersForTopic.get(i)).addAll(partitions.subList(start, start + length));
}
}
return assignment;
}
- 总结
由上面的分析可知,range策略会把无法整除的剩余分区,分配给前面几个消费者,而且每个topic都会如此。这样的话,topic越多,前面几个消费者可能承受的压力就越大。range的弊端还是非常明显的。
roundrobin策略
- 实现
org.apache.kafka.clients.consumer.RoundRobinAssignor
- 说明
roundrobin策略针对于全局所有的topic和消费者,分配步骤如下:
- 消费者按照字典排序,例如C0, C1, C2… …,并构造环形迭代器。
- topic名称按照字典排序,并得到每个topic的所有分区,从而得到所有分区集合。
- 遍历第2步所有分区集合,同时轮询消费者。
- 如果轮询到的消费者订阅的topic不包括当前遍历的分区所属topic,则跳过;否则分配给当前消费者,并继续第3步。
所以对于某个topic来说:
如果有5个分区(P0, P1, P2, P3, P4),且订阅这个topic的消费者组有2个消费者(C0, C1)。那么P0, P2, P4将被C0消费,P1, P3将被C1消费。
roundrobin策略如下图所示:
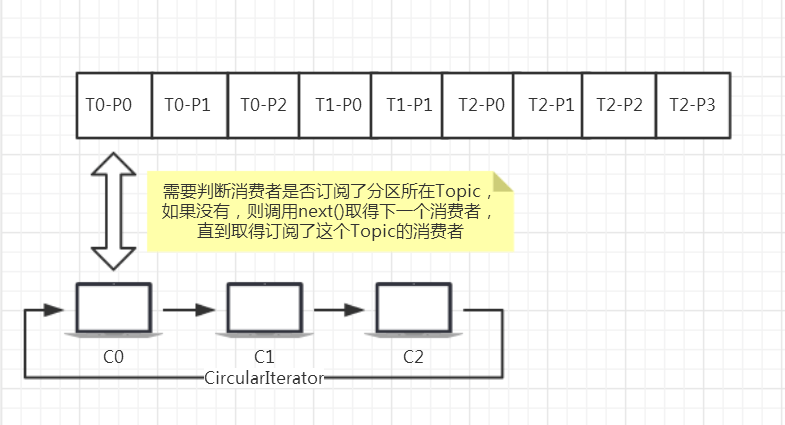
roundrobin策略
如图所示:
3个Topic:T0(3个分区0, 1, 2), T1(两个分区0, 1), T2(4个分区0, 1, 2, 3);
3个consumer: C0订阅了[T0, T1], C1订阅了[T1, T2], C2订阅了[T2, T0];
roundrobin结果分配结果如下:
T0-P0分配给C0,T0-P1分配给C2,T0-P2分配给C0,
T1-P0分配给C1,T1-P1分配给C0,
T2-P0分配给C1,T2-P1分配给C2,T2-P2分配给C1,T0-P3分配给C2;
推算过程:
分区T0-P0,消费者C0,C0订阅了这个分区所在Topic即T0,所以T0-P0分配给C0;
轮询到下一个分区T0-P1和下一个消费者C1;
分区T0-P1,消费者C1,C1没有订阅T0,取下一个消费者C2,C2订阅了T0,所以T0-P1分配给C2;
轮询到下一个分区T0-P2和下一个消费者C0;
分区T0-P2,消费者C0,C0订阅了T0,所以T0-P2分配给C0;
轮询到下一个分区T1-P0和下一个消费者C1;
分区T1-P0,消费者C1,C1订阅T1,所以T1-P0分配给C1;
以此类推即可。
- 源码注释
The round robin assignor lays out all the available partitions and all the available consumers. It then proceeds to do a round robin assignment from partition to consumer. If the subscriptions of all consumer instances are identical, then the partitions will be uniformly distributed. (i.e., the partition ownership counts will be within a delta of exactly one across all consumers.) For example, suppose there are two consumers C0 and C1, two topics t0 and t1, and each topic has 3 partitions, resulting in partitions t0p0, t0p1, t0p2, t1p0, t1p1, and t1p2. The assignment will be:
C0: [t0p0, t0p2, t1p1]
C1: [t0p1, t1p0, t1p2]
When subscriptions differ across consumer instances, the assignment process still considers each consumer instance in round robin fashion but skips over an instance if it is not subscribed to the topic. Unlike the case when subscriptions are identical, this can result in imbalanced assignments. For example, we have three consumers C0, C1, C2, and three topics t0, t1, t2, with 1, 2, and 3 partitions, respectively. Therefore, the partitions are t0p0, t1p0, t1p1, t2p0, t2p1, t2p2. C0 is subscribed to t0; C1 is subscribed to t0, t1; and C2 is subscribed to t0, t1, t2. Tha assignment will be:
C0: [t0p0]
C1: [t1p0]
C2: [t1p1, t2p0, t2p1, t2p2]
这段源码注释中,第一种情况比较好理解,第二种情况套用上面的分配步骤进行推算,过程如下:
- 消费者字典排序且构造成环形队列[C0, C1, C2];C0订阅了[t0],C1订阅了[t0, t1],C2订阅了[t0, t1, t2];
- topic字段排序即[t0, t1, t2],t0只有一个分区p0,t1有两个分区p0和p1,t2有三个分区p0,p1和p2。得到这三个topic下所有分区集合[t0p0, t1p0, t1p1, t2p0, t2p1, t2p2];
- 开始遍历所有分区。
- 遍历分区t0p0,同时消费者为C0,C0订阅了t0这个topic,所以分区t0p0分配给C0这个消费者;
- 遍历分区t1p0,同时消费者为C1(每次消费者都需要轮询),C1订阅了t1,所以分区t1p0分配给C1这个消费者;
- 遍历分区t1p1,同时消费者为C2,C2订阅了t1这个topic,所以分区t1p1分配给C1这个消费者;
- 遍历分区t2p0,同时消费者为C0,C0没有订阅t1,轮询到消费者C1,C1也没有订阅t2,轮询到C2,C2订阅了t2这个topic,所以分区t2p0分配给C2这个消费者;
- 遍历分区t2p1,同时消费者为C0,C0没有订阅t1,轮询到消费者C1,C1也没有订阅t2,轮询到C2,C2订阅了t2这个topic,所以分区t2p0分配给C2这个消费者;
- 遍历分区t2p2,同时消费者为C0,C0没有订阅t1,轮询到消费者C1,C1也没有订阅t2,轮询到C2,C2订阅了t2这个topic,所以分区t2p0分配给C2这个消费者;
- 遍历完所有分区,over。
over。
- 源码
核心源码如下:
// partitionsPerTopic表示topic和分区关系,key是topic,value是分区数量
// subscriptions表示订阅关系,key是消费者,value是订阅的topic信息
@Override
public Map<String, List<TopicPartition>> assign(Map<String, Integer> partitionsPerTopic,
Map<String, Subscription> subscriptions) {
Map<String, List<TopicPartition>> assignment = new HashMap<>();
for (String memberId : subscriptions.keySet())
assignment.put(memberId, new ArrayList<TopicPartition>());
// 将消费者集合先按照字典排序,再构造成一个环形迭代器
CircularIterator<String> assigner = new CircularIterator<>(Utils.sorted(subscriptions.keySet()));
// 以topic名称排序(SortedSet<String> topics = new TreeSet<>();TreeSet保存topic名称从而实现排序),遍历topic下的分区,得到全部分区(分区主要信息包括topic名称和分区编号)
for (TopicPartition partition : allPartitionsSorted(partitionsPerTopic, subscriptions)) {
final String topic = partition.topic();
// assigner.peek()得到最后一次遍历的消费者。如果遍历的当前分区所属topic不在最后一次遍历的消费者订阅的topic范围内,那么从环形迭代器中轮询选择下一个消费者,直到选择的消费者订阅的topic集合包含当前topic。
while (!subscriptions.get(assigner.peek()).topics().contains(topic))
assigner.next();
// 给消费者分配分区,并轮询到下一个消费者
assignment.get(assigner.next()).add(partition);
}
return assignment;
}
- CircularIterator
CircularIterator环形迭代器的实现比较简单,内部用一个List<T>存储数据,next()迭代时稍作改造即可,这个环形迭代器的作用就是轮询取值,上面的源码是轮询取消费者:
@Override
public T next() {
// i初始值为0
T next = list.get(i);
// 每次取值后,i的值+1,由于是环形迭代器,为了让i不超过List的最大下标,所以i对list.size()取模。
i = (i + 1) % list.size();
return next;
}
自定义(随机)策略
自定义实现非常简单,自定义类AfeiAssignor实现抽象类AbstractPartitionAssignor即可,核心源码如下:
/**
* 自定义实现的随机选择消费者分配器
* @author wangzhenfei9
* @version 1.0.0
* @since 2018年07月10日
*/
public class AfeiAssignor extends AbstractPartitionAssignor {
private Map<String, List<String>> consumersPerTopic(Map<String, Subscription> consumerMetadata) {
Map<String, List<String>> res = new HashMap<>();
for (Map.Entry<String, Subscription> subscriptionEntry : consumerMetadata.entrySet()) {
String consumerId = subscriptionEntry.getKey();
for (String topic : subscriptionEntry.getValue().topics()) {
put(res, topic, consumerId);
}
}
return res;
}
@Override
public Map<String, List<TopicPartition>> assign(Map<String, Integer> partitionsPerTopic,
Map<String, Subscription> subscriptions) {
// 得到topic和订阅该topic的消费者集合(参考RangeAssignor中的consumersPerTopic()方法)
Map<String, List<String>> consumersPerTopic = consumersPerTopic(subscriptions);
Map<String, List<TopicPartition>> assignment = new HashMap<>();
for (String memberId : subscriptions.keySet()) {
assignment.put(memberId, new ArrayList<>());
}
// 遍历每个topic
for (Map.Entry<String, List<String>> topicEntry : consumersPerTopic.entrySet()) {
String topic = topicEntry.getKey();
// 订阅当前topic的所有消费者集合
List<String> consumersForTopic = topicEntry.getValue();
int consumerSize = consumersForTopic.size();
Integer numPartitionsForTopic = partitionsPerTopic.get(topic);
if (numPartitionsForTopic == null) {
continue;
}
// 当前topic下所有分区
List<TopicPartition> partitions = AbstractPartitionAssignor.partitions(topic, numPartitionsForTopic);
for (TopicPartition partition:partitions){
// 随机选择一个消费者
int rand = new Random().nextInt(consumerSize);
// 得到随机选择的消费者
String selectedConsumer = consumersForTopic.get(rand);
// 给选择的消费者分配当前分区
assignment.get(selectedConsumer).add(partition);
}
}
System.out.println("分配结果: "+new Gson().toJson(assignment));
return assignment;
}
@Override
public String name() {
return "afei";
}
}
作者:阿飞的博客
来源:https://www.jianshu.com/p/91277c38fda6
看完两件小事
如果你觉得这篇文章对你挺有启发,我想请你帮我两个小忙:
- 把这篇文章分享给你的朋友 / 交流群,让更多的人看到,一起进步,一起成长!
- 关注公众号 「方志朋」,公众号后台回复「666」 免费领取我精心整理的进阶资源教程

本文著作权归作者所有,如若转载,请注明出处
转载请注明:文章转载自「 Java极客技术学习 」https://www.javajike.com
 微信扫一扫
微信扫一扫