
13. kafka集群内复制功能深入剖析
kafka是一个分布式发布订阅消息系统。由LinkedIn开发并已经在2011年7月成为apache顶级项目。kafka在LinkedIn, Twitte等许多公司都得到广泛使用,主要用于:日志聚合,消息队列,实时监控等。
0.8版本开始,kafka支持集群内复制,从而提高可用性和系统稳定性,这篇文章主要概述kafka复制的设计。
介绍
kafka不同于传统的消息系统:
- 分布式设计,并且易于扩展。
- 消息持久化,因此在某些场景批量消费,例如ETL,除了实时应用。
- 发布和订阅都有很高的吞吐量。
- 支持多个订阅者,并且在消费者出错时能自动均衡消费者。
复制
有了复制后,kafka客户端将会得到如下好处:
- 生产者能在出现故障的时候继续发布消息,并且能在延迟和持久性之间选择,取决于应用。
- 消费者能在出现故障的时候继续实时接受正确的消息。
所有的分布式系统必须在一致性,可用性,分区容错性之间进行权衡并做出取舍(参考CAP定理),我们的目标是在单个数据中心里的kafka集群也支持复制。网络分区是比较少见的,因此kafka设计专注于高可用和强一致。强一致意味着所有副本数据完全一致,这简化了应用程序开发人员的工作。
kafka是一个基于CA的系统(不确定),zookeeper是一个基于CP的系统(很确定),eureka是一个基于AP的系统(很确定)。
复制强一致
在文献中,有两种保持强一致性复制的典型方法。这两种方法都需要副本中的一个被设计为leader,所有写入都需要发布到该副本。leader负责处理所有的接入。并广播这些写到其他follower副本,并且要保证复制顺序和leader的顺序一致。
第一种方法是基于法定人数。leader等待直到大多数副本收到数据。当leader出现故障,大多数follower会协调选举出新的leader。这种方法被用于Apache Zookeeper 和Google’s Spanner.
第二种方法是leader等待所有副本收到数据(在kafka中这个"所有"是所有的In-Sync Replicas)。如果leader出现故障,其他副本能被选举为新的leader。
kafka复制选择的是第二种方法,有两个主要原因:
- 相同数量的副本情况下,第二种方法能承受更多的容错。例如,总计2f+1个副本,第二种方法能承受2f个副本故障,而第一种方法只能承受f个副本故障。如果在只有两个副本的情况下,第一种方法不能容忍任意一个副本故障。
- 第一种方法延迟性表现更好,因为只需要法定人数确认即可,所以会隐藏掉一些比较慢的副本的影响。而kafka副本被设计在相同的数据中心的一个集群下。所以网络延迟这种变数是比较小的。
术语
为了了解kafka中的副本是如何实现的,我们首先需要介绍一些基本概念。在kafka中,消息流由topic定义,topic被切分为1个或者多个分区(partition),复制发生在分区级别,每个分区有一个或者多个副本。
副本被均匀分配到kafka集群的不同服务器(称为broker)上。每个副本都维护磁盘上的日志。生产者发布的消息顺序追加到日志中,日志中每条消息被一个单调递增的offset标识。
offset是分区内的逻辑概念, 给定偏移量,可以在分区的每个副本中标识相同的消息。 当消费者订阅某个主题时,它会跟踪每个分区中的偏移量以供使用,并使用它来向broker发出获取消息的请求。
实现
kafka复制示意图如下所示:
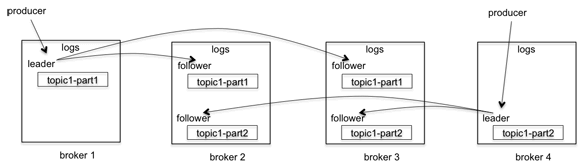

kafka_replication_diagram.png
- 集群总计4个broker(broker1~broker4);
- 一个topic,两个分区,三个副本;
- 分区1即topic1-part1的leader在broker1上,分区2即topic1-part2的leader在broker4上;
- producer写入消息到分区topic1-part1的leader上,然后复制到它的两个副本,分别在broker2和broker3上。
- producer写入消息到分区topic1-part2的leader上,然后复制到它的两个副本,分别在broker2和broker3上。
当生产者发布消息到topic的某个分区时,消息首先被传递到leader副本,并追加日志。follower副本从leader中不停的拉取新消息,一旦有足够的副本收到消息,leader就会提交这个消息。
这里有个问题,leader是怎么决定什么是足够的。kafka维护了一个 in-sync replica(ISR)集合。这个ISR副本集都是存活的,并且完全赶上leader的副本,没有消息延迟(leader总是在ISR集合中)。当分区初始化创建时,每个副本都在ISR集合中。当新消息发布后,leader提交消息前一直等待直到所有ISR副本收到消息。如果某个follower副本故障,它将会被从ISR中移除。leader会继续提交新的消息,只不过ISR数量相比分区创建时副本数量更少。
请注意,现在,系统运行在under replicated模式。
leader还会维护high watermark (HW,这个词语也不打算翻译,会变味),是指分区中最后一次提交消息的offset。HW会不断传播给follower副本,定期检查每个broker的磁盘并恢复。
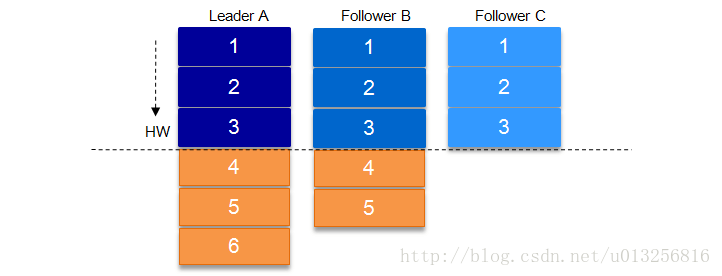
kafka high watermark.png
图片来源于朱小厮的博客:https://blog.csdn.net/u013256816/article/details/71091774
当一个故障副本被重启后,它首先从磁盘上恢复最新的HW,并将日志截断到HW。这是必要的,因为不能保证在HW之后的消息被提交,所以可能需要丢弃。然后副本成为follower,并继续从leader那里获取HW以后的消息。一旦完全赶上leader,这个副本从新被加入到ISR中。系统将重新回到fully replicated模式。
故障处理
kafka依赖zookeeper检测broker故障,我们会用一个controller(broker集合中的一个)接收所有zookeeper关于故障,选举新leader等相关通知,这样还有一个好处,减少了对zookeeper的压力。如果某个leader故障,controller就会从ISR副本中选举一个新的leader,并发布新leader的消息给其他follower。
按照设计,leader选举过程中,已经提交的消息总是会被保留,一些未提交的消息可能会丢失。leader和每个分区的ISR也会被保存在Zookeeper中,controller出现故障转移时需要用到。由于故障一般会很少,预期的leader和ISR都会不经常改变。
对客户端来说,broker仅向消费者公开已经提交的消息。broker故障期间,已提交的数据始终被保留。消费者使用相同的offset可以从另一个副本拉取消息。
生产者能选择在broker收到消息后何时得到broker的确认。例如,它能等到消息被leader提交(要求所有ISR接收到消息,即acks=-1)。另外,也可以选择消息只要被leader追加到日志中,可能还没有提交(acks=0或者1)。前一种情况即acks=-1,生产者需要等待更长的时间。但是确认的消息都保证在broker中保留。后一种情况即acks=0或者1,生产者有更低的延迟,但一些确认的消息在broker故障时可能会丢失。如何抉择,由你决定。
更多
请参考https://cwiki.apache.org/confluence/display/KAFKA/Kafka+Replication
原文地址:https://engineering.linkedin.com/kafka/intra-cluster-replication-apache-kafka
作者:阿飞的博客
来源:https://www.jianshu.com/p/03d6a335237f
看完两件小事
如果你觉得这篇文章对你挺有启发,我想请你帮我两个小忙:
- 把这篇文章分享给你的朋友 / 交流群,让更多的人看到,一起进步,一起成长!
- 关注公众号 「方志朋」,公众号后台回复「666」 免费领取我精心整理的进阶资源教程

本文著作权归作者所有,如若转载,请注明出处
转载请注明:文章转载自「 Java极客技术学习 」https://www.javajike.com
 微信扫一扫
微信扫一扫