
17. SQL重写为limit Integer.MAX_VALUE的无奈
阿飞Javaer,转载请注明原创出处,谢谢!
这篇文章源于sharding-jdbc源码分析之重写的遗留问题,相关sharding-jdbc源码如下:
private void appendLimitRowCount(final SQLBuilder sqlBuilder, final RowCountToken rowCountToken, final int count, final List<SQLToken> sqlTokens, final boolean isRewrite) {
SelectStatement selectStatement = (SelectStatement) sqlStatement;
Limit limit = selectStatement.getLimit();
if (!isRewrite) {
... ...
} else if ((!selectStatement.getGroupByItems().isEmpty() || !selectStatement.getAggregationSelectItems().isEmpty()) && !selectStatement.isSameGroupByAndOrderByItems()) {
// 如果要重写sql中的limit的话,且sql中有group by或者有group by & order by,例如"select user_id, sum(score) from t_order group by user_id order by sum(score) desc limit 5",那么limit 5需要重写为limit Integer.MAX_VALUE,原因接下来分析
sqlBuilder.appendLiterals(String.valueOf(Integer.MAX_VALUE));
} else {
... ...
}
... ...
}
构造数据
为了解释为什么limit rowCount中的rowCount需要重写为Integer.MAX_VALUE,需要先构造一些数据,如下图所示:
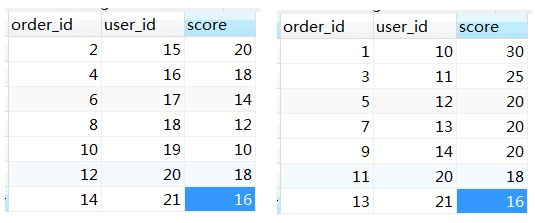

t_order_0 & t_order_1两个分表中的数据
如果不分库分表的话,数据如下图所示:
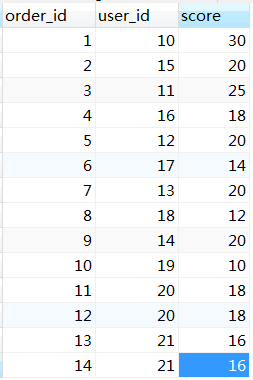
t_order表中的数据
执行SQL
假定执行如下SQL:
select user_id, sum(score) from t_order group by user_id order by sum(score) desc limit 5;
结果如下所示:
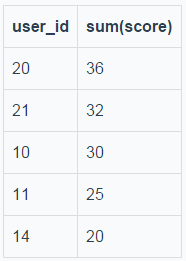
image.png
假定select user_id, sum(score) from t_order group by user_id order by sum(score) desc limit 5;这个SQL不重写为limit 0, Integer.MAX_VALUE,那么t_order_0和t_order_1的结果分别如下;
t_order_0的结果:
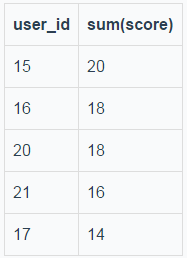
image.png
t_order_1的结果:
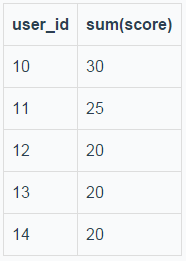
image.png
路由到两个表的执行结果归并后的结果如下:
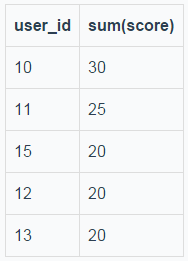
image.png
分析
根据执行结果可知,主要差异在于,真实结果有user_id为20,21的数据。我们在看一下t_order_0和t_order_1两个分表中这两个user_id的数据有什么特殊之处:
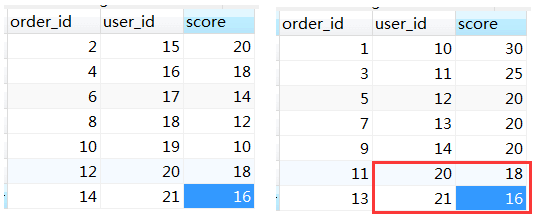
image.png
在t_order_1这个分表中,由于user_id为20,21的score值在TOP 5以外。但是合并t_order_0和t_order_1两个分表的结果,user_id为20的sum(score)能够排在第一(18+18=36);所以,如果group by这类的SQL不重写为limit 0, Integer.MAX_VALUE的话,会导致结果有误。所以sharding-jdbc的源码必须要这样重写,没有其他办法!
延伸
事实上不只是sharding-jdbc,任何有sharding概念的中间件例如ElasticSearch,都要这么处理,因为sharding后数据处理的流程几乎都要经过解析->重写->路由->执行->结果归并这几个阶段;所以,当我们的数据是以分片的方式存储时(分库分表,ElasticSearch等),尽量保证CRUD只路由到一个分片上。最起码要保证那些高并发低延迟的CRUD只路由到一个分片上,所以,sharding column的选取非常非常重要。
作者:阿飞的博客
来源:https://www.jianshu.com/p/e541ac380e18
看完两件小事
如果你觉得这篇文章对你挺有启发,我想请你帮我两个小忙:
- 把这篇文章分享给你的朋友 / 交流群,让更多的人看到,一起进步,一起成长!
- 关注公众号 「方志朋」,公众号后台回复「666」 免费领取我精心整理的进阶资源教程

本文著作权归作者所有,如若转载,请注明出处
转载请注明:文章转载自「 Java极客技术学习 」https://www.javajike.com
 微信扫一扫
微信扫一扫