
22.sharding-jdbc源码之INSERT解析
阿飞Javaer,转载请注明原创出处,谢谢!
INSERT语法
分析insert解析之前,首先看一下mysql官方对insert语法的定义,因为SQL解析跟语法息息相关:
INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name
[PARTITION (partition_name [, partition_name] ...)]
[(col_name [, col_name] ...)]
{VALUES | VALUE} (value_list) [, (value_list)] ...
[ON DUPLICATE KEY UPDATE assignment_list]
INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name
[PARTITION (partition_name [, partition_name] ...)]
SET assignment_list
[ON DUPLICATE KEY UPDATE assignment_list]
INSERT [LOW_PRIORITY | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name
[PARTITION (partition_name [, partition_name] ...)]
[(col_name [, col_name] ...)]
SELECT ...
[ON DUPLICATE KEY UPDATE assignment_list]
INSERT解析
接下来分析sharding-jdbc是如何解析insert类型的SQL语句的,通过SQLStatement result = sqlParser.parse();得到SQL解析器后,执行AbstractInsertParser中parse()方法解析insert sql,核心源码如下:
@Override
public final DMLStatement parse() {
lexerEngine.nextToken();
InsertStatement result = new InsertStatement();
insertClauseParserFacade.getInsertIntoClauseParser().parse(result);
insertClauseParserFacade.getInsertColumnsClauseParser().parse(result);
if (lexerEngine.equalAny(DefaultKeyword.SELECT, Symbol.LEFT_PAREN)) {
throw new UnsupportedOperationException("Cannot INSERT SELECT");
}
insertClauseParserFacade.getInsertValuesClauseParser().parse(result);
insertClauseParserFacade.getInsertSetClauseParser().parse(result);
appendGenerateKey(result);
return result;
}
对应的泳道图如下所示:
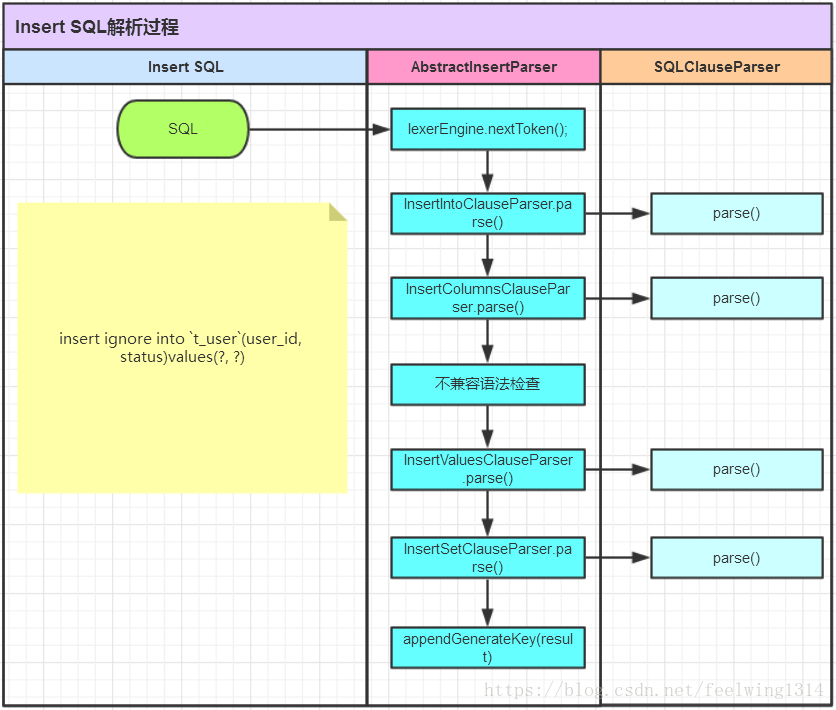

INSERT解析泳道图
第1步-lexerEngine.nextToken()
由parse()源码可知,insert解析第1步就是调用 lexerEngine.nextToken(),nextToken()在之前的文章已经分析过(戳链接),即跳到下一个token,由于任意SQL解析都会在SQLParsingEngine中调用lexerEngine.nextToken(),这里再调用lexerEngine.nextToken(),所以总计已经跳过两个token。
为什么要一开始就调用nextToken()呢?回到insert的语法:INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE] [INTO] tbl_name~~~,INSERT INTO一定会有, LOW_PRIORITY,DELAYED ,HIGH_PRIORITY和IGNORE几个关键词可选,即在表名之前,至少有两个token。所以跳过两个token后再进行下一步操作(SQLParsingEngine.parse()中调用了一次nextToken(),这里再调用一次nextToken());
第2步-InsertIntoClauseParser.parse(result)
由parse()源码可知,insert解析第2步就是调用 insertClauseParserFacade.getInsertIntoClauseParser().parse(result);,即解析insert into后面的表名,封装到InsertStatement的table属性中,核心源码如下所示:
- 检查是否有不支持的关键词(跳过两个token后,只有Oracle有两个不支持的关键词:ALL和FIRST);
- 跳到INTO(因为INSERT和INTO之间还有其他关键词,在此之前即使调用了两次nextToken(),当前token也不一定就是INTO);
- 获取下一个token即表名(根据insert语法可知,INTO后肯定是表名。表名token值:Token(type=IDENTIFIER, literals=`t_user`, endPosition=27));
- 解析表名赋值给InsertStatement;
- 如果表名和VALUES关键词之间有其他关键词则跳过(例如MySQL的分区insert语法:
INSERT [LOW_PRIORITY | HIGH_PRIORITY] [IGNORE] [INTO] tbl_name [PARTITION (partition_name [, partition_name] ... ...)
public void parse(final InsertStatement insertStatement) {
// step1
lexerEngine.unsupportedIfEqual(getUnsupportedKeywordsBeforeInto());
// step2
lexerEngine.skipUntil(DefaultKeyword.INTO);
// step3
lexerEngine.nextToken();
// step4
tableReferencesClauseParser.parse(insertStatement, true);
// step5
skipBetweenTableAndValues(insertStatement);
}
第3步-InsertColumnsClauseParser.parse()
由parse()源码可知,insert解析第3步就是调用 insertClauseParserFacade.getInsertColumnsClauseParser().parse(result);,即解析insert into t_user后面的列,封装到InsertStatement的columns属性中,核心源码如下所示:
public void parse(final InsertStatement insertStatement) {
Collection<Column> result = new LinkedList<>();
// 如果当前token是(,即左括号,那么尝试解析括号里的insert的列名
if (lexerEngine.equalAny(Symbol.LEFT_PAREN)) {
// 得到insert的目标表名
String tableName = insertStatement.getTables().getSingleTableName();
Optional<String> generateKeyColumn = shardingRule.getGenerateKeyColumn(tableName);
int count = 0;
do {
// 调用nextToken()解析到insert的某一列
lexerEngine.nextToken();
// 得到列名
String columnName = SQLUtil.getExactlyValue(lexerEngine.getCurrentToken().getLiterals());
// 封装到Column中添加到最后的结果中
result.add(new Column(columnName, tableName));
// 调用nextToken()进行解析(如果还没到最后就是都好,否则就是右括号)
lexerEngine.nextToken();
// 如果存在主键(例如id),并且当前解析的列刚好是主键列,那么记录下主键列的位置(generateKeyColumnIndex)
if (generateKeyColumn.isPresent() && generateKeyColumn.get().equalsIgnoreCase(columnName)) {
insertStatement.setGenerateKeyColumnIndex(count);
}
count++;
// 如果遍历到右括号,或者SQL最后,就停止解析
} while (!lexerEngine.equalAny(Symbol.RIGHT_PAREN) && !lexerEngine.equalAny(Assist.END));
// 记录下insert最后一列的位置,即右括号前的位置,例如"insert ignore into `t_user`(user_id, status) values(? , ?)"这个SQL的status所在位置
insertStatement.setColumnsListLastPosition(lexerEngine.getCurrentToken().getEndPosition() - lexerEngine.getCurrentToken().getLiterals().length());
lexerEngine.nextToken();
}
// 将遍历得到的所有insert的列赋值给InsertStatement中的columns属性
insertStatement.getColumns().addAll(result);
}
第4步-不支持的语法检查
由parse()源码可知,insert解析第4步就是调用如下代码,即检查是否有sharding-jdbc不支持的insert ... select ...语法(例如insert ignore into t_user(user_id, status) select 18, ‘VALID’ from dual),如果有就抛出UnsupportedOperationException异常:
if (lexerEngine.equalAny(DefaultKeyword.SELECT, Symbol.LEFT_PAREN)) {
throw new UnsupportedOperationException("Cannot INSERT SELECT");
}
第5步-InsertValuesClauseParser.parse()
由parse()源码可知,insert解析第5步就是调用 insertClauseParserFacade.getInsertValuesClauseParser().parse(result);,即解析insert into sql中的value集合,封装到InsertStatement的conditions属性中,通过Conditions.add()源码可知,只会添加sharding列的值,例如insert ignore into t_user(id, user_id, status)values(?, ?, ?)只有user_id是sharding列,所以只会添加它:
public void add(final Condition condition, final ShardingRule shardingRule) {
if (shardingRule.isShardingColumn(condition.getColumn())) {
conditions.put(condition.getColumn(), condition);
}
}
第6步-InsertSetClauseParser.parse()
由parse()源码可知,insert解析第6步就是调用 insertClauseParserFacade.getInsertSetClauseParser().parse(result);,即解析insert into … set …这种语法的SQL,例如:insert into t_user set id=24, user_id=24, status='NEW';核心源码如下所示:
public void parse(final InsertStatement insertStatement) {
// 即如果不是**insert into ... set ...**这种语法,那么return,不需要继续往下解析
if (!lexerEngine.skipIfEqual(new Keyword[] {DefaultKeyword.SET})) {
return;
}
do {
Column column = new Column(SQLUtil.getExactlyValue(lexerEngine.getCurrentToken().getLiterals()), insertStatement.getTables().getSingleTableName());
lexerEngine.nextToken();
lexerEngine.accept(Symbol.EQ);
SQLExpression sqlExpression;
// 分析token, 根据不同类型得到不用的SQLExpression
if (lexerEngine.equalAny(Literals.INT)) {
sqlExpression = new SQLNumberExpression(Integer.parseInt(lexerEngine.getCurrentToken().getLiterals()));
} else if (lexerEngine.equalAny(Literals.FLOAT)) {
sqlExpression = new SQLNumberExpression(Double.parseDouble(lexerEngine.getCurrentToken().getLiterals()));
} else if (lexerEngine.equalAny(Literals.CHARS)) {
sqlExpression = new SQLTextExpression(lexerEngine.getCurrentToken().getLiterals());
} else if (lexerEngine.equalAny(DefaultKeyword.NULL)) {
sqlExpression = new SQLIgnoreExpression(DefaultKeyword.NULL.name());
} else if (lexerEngine.equalAny(Symbol.QUESTION)) {
sqlExpression = new SQLPlaceholderExpression(insertStatement.getParametersIndex());
insertStatement.increaseParametersIndex();
} else {
throw new UnsupportedOperationException("");
}
lexerEngine.nextToken();
if (lexerEngine.equalAny(Symbol.COMMA, DefaultKeyword.ON, Assist.END)) {
// 说明,这里只会添加数据库或者表的sharding列
insertStatement.getConditions().add(new Condition(column, sqlExpression), shardingRule);
} else {
lexerEngine.skipUntil(Symbol.COMMA, DefaultKeyword.ON);
}
} while (lexerEngine.skipIfEqual(Symbol.COMMA));
}
第7步-appendGenerateKey(result)
由parse()源码可知,insert解析第7步就是调用 appendGenerateKey(result),即如果TableRule申明了.generateKeyColumn("id", MyKeyGenerator.class),并且SQL中没有主键列,那么InsertStatement的sqlTokens还需要增加两个token:ItemsToken和GeneratedKeyToken,核心源码如下:
private void appendGenerateKey(final InsertStatement insertStatement) {
String tableName = insertStatement.getTables().getSingleTableName();
Optional<String> generateKeyColumn = shardingRule.getGenerateKeyColumn(tableName);
// generateKeyColumn存在,即generateKeyColumn.isPresent(),即TableRule定义时指定了.generateKeyColumn();例如TableRule.generateKeyColumn("id", MyKeyGenerator.class)
if (!generateKeyColumn.isPresent()) {
return;
}
// Insert SQL语句中没有TableRule定义时TableRule.generateKeyColumn("id")指定的列,例如id;
if (null != insertStatement.getGeneratedKey()) {
return;
}
ItemsToken columnsToken = new ItemsToken(insertStatement.getColumnsListLastPosition());
columnsToken.getItems().add(generateKeyColumn.get());
insertStatement.getSqlTokens().add(columnsToken);
insertStatement.getSqlTokens().add(new GeneratedKeyToken(insertStatement.getValuesListLastPosition()));
}
ItemsToken和GeneratedKeyToken这两个token用于后面的SQL重写,例如将insert ignore into t_user(user_id, status) values(? , ?)这样的SQL重写为insert ignore into t_user(user_id, status, id) values(? , ?, ?)
作者:阿飞的博客
来源:https://www.jianshu.com/p/2f3593f27bb7
看完两件小事
如果你觉得这篇文章对你挺有启发,我想请你帮我两个小忙:
- 把这篇文章分享给你的朋友 / 交流群,让更多的人看到,一起进步,一起成长!
- 关注公众号 「方志朋」,公众号后台回复「666」 免费领取我精心整理的进阶资源教程

本文著作权归作者所有,如若转载,请注明出处
转载请注明:文章转载自「 Java极客技术学习 」https://www.javajike.com
 微信扫一扫
微信扫一扫