
6. sharding-jdbc源码之group by结果合并(1)
阿飞Javaer,转载请注明原创出处,谢谢!
在5. sharding-jdbc源码之结果合并中已经分析了OrderByStreamResultSetMerger、LimitDecoratorResultSetMerger、IteratorStreamResultSetMerger,查看源码目录下ResultSetMerger的实现类,只剩下GroupByMemoryResultSetMerger和GroupByStreamResultSetMerger两个实现类的分析,接下来根据源码对两者的实现进行剖析;
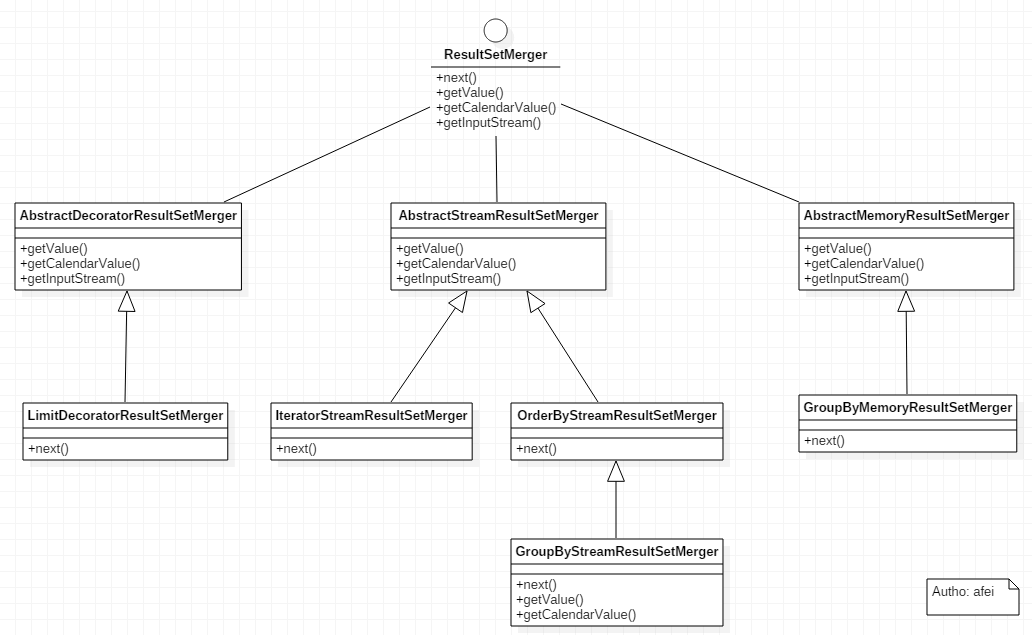

ResultSetMerge关系图.png
如何选择
GroupBy有两个ResultSetMerge的实现:GroupByMemoryResultSetMerger和GroupByStreamResultSetMerger,那么如何选择呢?在MergeEngine中有一段这样的代码:
private ResultSetMerger build() throws SQLException {
// 如果有group by或者聚合类型(例如sum, avg等)的SQL条件,就会选择一个GroupBy***ResultSetMerger
if (!selectStatement.getGroupByItems().isEmpty() || !selectStatement.getAggregationSelectItems().isEmpty()) {
// isSameGroupByAndOrderByItems()源码紧随其后
if (selectStatement.isSameGroupByAndOrderByItems()) {
return new GroupByStreamResultSetMerger(columnLabelIndexMap, resultSets, selectStatement);
} else {
return new GroupByMemoryResultSetMerger(columnLabelIndexMap, resultSets, selectStatement);
}
}
if (!selectStatement.getOrderByItems().isEmpty()) {
return new OrderByStreamResultSetMerger(resultSets, selectStatement.getOrderByItems());
}
return new IteratorStreamResultSetMerger(resultSets);
}
// 如果只有group by条件,没有order by,那么isSameGroupByAndOrderByItems()为true,例如:`SELECT o.* FROM t_order o where o.user_id=? group by o.order_id`(因为这种sql会被改写为SELECT o.* , o.order_id AS GROUP_BY_DERIVED_0 FROM t_order_0 o where o.user_id=? group by o.order_id ORDER BY GROUP_BY_DERIVED_0 ASC,即group by和order by完全相同)
public boolean isSameGroupByAndOrderByItems() {
return !getGroupByItems().isEmpty() && getGroupByItems().equals(getOrderByItems());
}
由上段源码分析可知,如果只有group by条件,那么选择GroupByStreamResultSetMerger;那么如果既有group by,又有order by,那么就会选择GroupByStreamResultSetMerger;
接下来分析GroupByStreamResultSetMerger中如何对结果进行group by聚合,假设数据源js_jdbc_0中实际表t_order_0和实际表t_order_1的数据如下:
| order_id | user_id | status |
|---|---|---|
| 1000 | 10 | INIT |
| 1002 | 10 | INIT |
| 1004 | 10 | VALID |
| 1006 | 10 | NEW |
| 1008 | 10 | INIT |
| order_id | user_id | status |
|---|---|---|
| 1001 | 10 | NEW |
| 1003 | 10 | NEW |
| 1005 | 10 | VALID |
| 1007 | 10 | INIT |
| 1009 | 10 | INIT |
GroupByStreamResultSetMerger
以执行SQLSELECT o.status, count(o.user_id) FROM t_order o where o.user_id=10 group by o.status为例,分析GroupByStreamResultSetMerger,其部分源码如下:
public final class GroupByStreamResultSetMerger extends OrderByStreamResultSetMerger {
... ...
public GroupByStreamResultSetMerger(
final Map<String, Integer> labelAndIndexMap, final List<ResultSet> resultSets, final SelectStatement selectStatement) throws SQLException {
// GroupByStreamResultSetMerger的父类是OrderByStreamResultSetMerger,所以调用super()就是调用OrderByStreamResultSetMerger的构造方法
super(resultSets, selectStatement.getOrderByItems());
// 标签(列名)和位置索引的map关系,例如{order_id:1, status:3, user_id:2}
this.labelAndIndexMap = labelAndIndexMap;
// 执行的SQL语句
this.selectStatement = selectStatement;
currentRow = new ArrayList<>(labelAndIndexMap.size());
// 如果优先级队列不为空,表示where条件中有group by,将队列中第一个元素的group值赋值给currentGroupByValues,即INIT(默认升序排列,所以INIT > NEW > VALID)
currentGroupByValues = getOrderByValuesQueue().isEmpty() ? Collections.emptyList() : new GroupByValue(getCurrentResultSet(), selectStatement.getGroupByItems()).getGroupValues();
}
...
}
备注:OrderByStreamResultSetMerger在5. sharding-jdbc源码之结果合并这篇文章中已经分析,不再赘述;
next()方法核心源码如下:
@Override
public boolean next() throws SQLException {
currentRow.clear();
// 如果优先级队列为空,表示没有任何结果,那么返回false
if (getOrderByValuesQueue().isEmpty()) {
return false;
}
if (isFirstNext()) {
super.next();
}
// 集合的核心逻辑在这里
if (aggregateCurrentGroupByRowAndNext()) {
currentGroupByValues = new GroupByValue(getCurrentResultSet(), selectStatement.getGroupByItems()).getGroupValues();
}
return true;
}
aggregateCurrentGroupByRowAndNext()实现如下:
private boolean aggregateCurrentGroupByRowAndNext() throws SQLException {
boolean result = false;
// selectStatement.getAggregationSelectItems()先得到select所有举行类型的项,例如select count(o.user_id) ***中聚合项是count(o.user_id), 然后转化成map,key就是聚合项即o.user_id,value就是集合unit实例即AccumulationAggregationUnit;即o.user_id的COUNT集合计算是通过AccumulationAggregationUnit实现的,下面有对AggregationUnitFactory的分析
Map<AggregationSelectItem, AggregationUnit> aggregationUnitMap = Maps.toMap(selectStatement.getAggregationSelectItems(), new Function<AggregationSelectItem, AggregationUnit>() {
@Override
public AggregationUnit apply(final AggregationSelectItem input) {
return AggregationUnitFactory.create(input.getType());
}
});
// 接下来准备聚合,如何group by的值相同,则进行聚合(因为SQL可能会在多个数据源以及多个实际表上执行)
while (currentGroupByValues.equals(new GroupByValue(getCurrentResultSet(), selectStatement.getGroupByItems()).getGroupValues())) {
// 调用aggregate()方法进行䄦
aggregate(aggregationUnitMap);
cacheCurrentRow();
// 调用next()方法,实际调用OrderByStreamResultSetMerger中的next()方法,currentResultSet会指向下一个元素;
result = super.next();
// 如果还有值,那么继续遍历
if (!result) {
break;
}
}
setAggregationValueToCurrentRow(aggregationUnitMap);
return result;
}
AggregationUnitFactory 源码如下:
public final class AggregationUnitFactory {
/**
* Create aggregation unit instance.
* 根据这段代码可知,select中MAX和MIN这种聚合查询需要使用ComparableAggregationUnit,SUM和COUNT需要使用AccumulationAggregationUnit,AVG需要使用AverageAggregationUnit;(目前只支持这些聚合操作),
*/
public static AggregationUnit create(final AggregationType type) {
switch (type) {
case MAX:
return new ComparableAggregationUnit(false);
case MIN:
return new ComparableAggregationUnit(true);
case SUM:
case COUNT:
return new AccumulationAggregationUnit();
case AVG:
return new AverageAggregationUnit();
default:
throw new UnsupportedOperationException(type.name());
}
}
}
aggregate()源码如下:
private void aggregate(final Map<AggregationSelectItem, AggregationUnit> aggregationUnitMap) throws SQLException {
for (Entry<AggregationSelectItem, AggregationUnit> entry : aggregationUnitMap.entrySet()) {
List<Comparable<?>> values = new ArrayList<>(2);
if (entry.getKey().getDerivedAggregationSelectItems().isEmpty()) {
values.add(getAggregationValue(entry.getKey()));
} else {
for (AggregationSelectItem each : entry.getKey().getDerivedAggregationSelectItems()) {
values.add(getAggregationValue(each));
}
}
// aggregate()的核心就是调用AggregationUnit具体实现中的merge()方法,即调用AccumulationAggregationUnit.merge()方法(后面会对AggregationUnit的各个实现进行分析)
entry.getValue().merge(values);
}
}
执行过程图解
这一块的代码逻辑稍微有点复杂,下面通过示意图分解执行过程,让sharding-jdbc执行group by整个过程更加清晰:
step1. SQL执行
首先在两个实际表t_order_0和t_order_1中分别执行SQL:SELECT o.status, count(o.user_id) FROM t_order o where o.user_id=10 group by o.status,t_order_0和t_order_1分别得到如下的结果:
| status | count(o.user_id) |
|---|---|
| INIT | 3 |
| NEW | 1 |
| VALID | 1 |
| status | count(o.user_id) |
|---|---|
| INIT | 2 |
| NEW | 2 |
| VALID | 1 |
step2. 执行super(***)
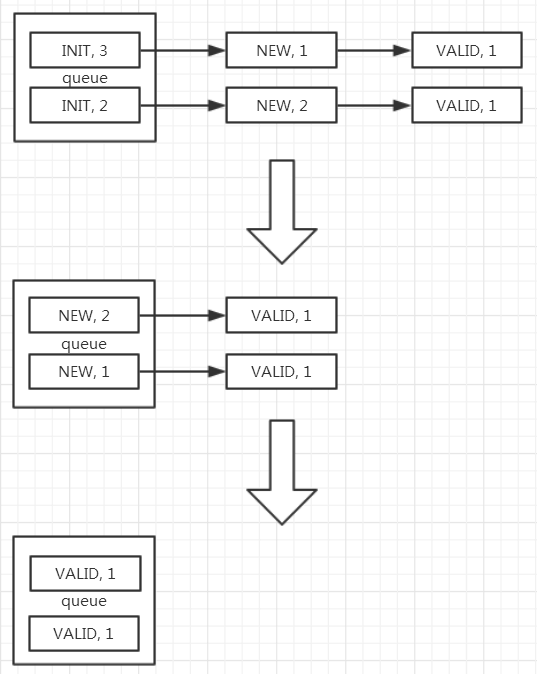
即在GroupByStreamResultSetMerger中调用OrderByStreamResultSetMerger的构造方法super(resultSets, selectStatement.getOrderByItems());,从而得到优先级队列,如下图所示的第一张图,优先级中包含两个元素[(INIT, 3), (INIT 2)]:
powered by afei.png
- 先聚合计算(INIT,3)和(INIT,2),由于NEW和INIT不相等,进行下一轮聚合计算;
- 再聚合计算(NEW,1)和(NEW,2),由于VALID和NEW不相等,进行下一轮聚合计算;
- 再聚合计算(VALID,1)和(VALID,1),两者的next()为false,聚合计算完成;
step3. aggregationUnitMap
通过转换得到aggregationUnitMap,key就是count(user_id),value就是COUNT聚合计算的AggregationUnit实现,即AccumulationAggregationUnit;
由于select语句中只有COUNT(o.user_id涉及到聚合运行,所以这个map的size为1,且key是count(user_id);如果SQL是
SELECT o.status, count(o.user_id), max(order_id) FROM t_order o where o.user_id=? group by o.status,那么aggregationUnitMap的size为2,且第一个entry的key是count(user_id),value是AccumulationAggregationUnit;第二个entry的key是max(order_id),value是ComparableAggregationUnit;
step4. 循环遍历并merge
核心代码如下,即将(INIT, 3)和(INIT, 2)通过调用AccumulationAggregationUnit中的merge方法,从而得到(INIT, 5)。同样的原因调用AccumulationAggregationUnit中的merge方法merge(NEW, 1)和(NEW, 2),从而得到(NEW, 3);merge(VALID, 1)和(VALID, 1),从而得到(VALID, 2)。所以,最终的结果就是[(INIT, 5), (NEW, 3), (VALID, 2)]
while (currentGroupByValues.equals(new GroupByValue(getCurrentResultSet(), selectStatement.getGroupByItems()).getGroupValues())) {
aggregate(aggregationUnitMap);
cacheCurrentRow();
result = super.next();
if (!result) {
break;
}
}
AggregationUnit
AggregationUnit即聚合计算接口,总计有三个实现类AccumulationAggregationUnit,ComparableAggregationUnit和AverageAggregationUnit,接下来分别对其简单介绍;
AccumulationAggregationUnit
实现源码如下,SUN和COUNT两个聚合计算都是用这个AggregationUnit实现,核心实现就是累加:
@Override
public void merge(final List<Comparable<?>> values) {
if (null == values || null == values.get(0)) {
return;
}
if (null == result) {
result = new BigDecimal("0");
}
// 核心实现代码:累加
result = result.add(new BigDecimal(values.get(0).toString()));
log.trace("Accumulation result: {}", result.toString());
}
ComparableAggregationUnit
实现源码如下,MAX和MIN两个聚合计算都是用这个AggregationUnit实现,核心实现就是比较:
@Override
public void merge(final List<Comparable<?>> values) {
if (null == values || null == values.get(0)) {
return;
}
if (null == result) {
result = values.get(0);
log.trace("Comparable result: {}", result);
return;
}
// 新的值与旧的值比较大小
int comparedValue = ((Comparable) values.get(0)).compareTo(result);
// 升序和降序比较方式不同(max聚合计算时asc为false,min聚合计算时asc为true),min聚合计算时找一个更小的值(asc && comparedValue < 0),max聚合计算时找一个更大的值(!asc && comparedValue > 0)
if (asc && comparedValue < 0 || !asc && comparedValue > 0) {
result = values.get(0);
log.trace("Comparable result: {}", result);
}
}
AverageAggregationUnit
实现源码如下,AVG聚合计算就是用的这个AggregationUnit实现,核心实现是将AVG转化后的SUM/COUNT,累加得到总SUM和总COUNT相除就是最终的AVG结果;
@Override
public void merge(final List<Comparable<?>> values) {
if (null == values || null == values.get(0) || null == values.get(1)) {
return;
}
if (null == count) {
count = new BigDecimal("0");
}
if (null == sum) {
sum = new BigDecimal("0");
}
// COUNT累加
count = count.add(new BigDecimal(values.get(0).toString()));
// SUM累加
sum = sum.add(new BigDecimal(values.get(1).toString()));
log.trace("AVG result COUNT: {} SUM: {}", count, sum);
}
作者:阿飞的博客
来源:https://www.jianshu.com/p/a7c46bffea34
看完两件小事
如果你觉得这篇文章对你挺有启发,我想请你帮我两个小忙:
- 把这篇文章分享给你的朋友 / 交流群,让更多的人看到,一起进步,一起成长!
- 关注公众号 「方志朋」,公众号后台回复「666」 免费领取我精心整理的进阶资源教程

本文著作权归作者所有,如若转载,请注明出处
转载请注明:文章转载自「 Java极客技术学习 」https://www.javajike.com
 微信扫一扫
微信扫一扫