
分库分表中间件华山论剑
分库分表中间件
分库分表的缺点:
- 引入分布式事务的问题;
- 跨节点 Join 的问题;
- 跨节点合并排序分页等聚合类SQL问题;
- 多数据源管理问题;
- 扩容缩容,数据迁移等问题;
分库分表的经验:
- 第一原则:能不切分尽量不要切分。
- 第二原则:如果要切分一定要选择合适的切分规则,提前规划好。
- 第三原则:数据切分尽量通过数据冗余或表分组(Table Group)来降低跨库 Join 的可能。
- 第四原则:由于数据库中间件对数据 Join 实现的优劣难以把握,而且实现高性能难度极大,业务读取尽量少使用多表 Join。
接下来主要比较cobar,mycat,sharding-jdbc三个人气较高的分库分表中间件;
1. cobar
Cobar is a proxy for sharding databases and tables,compatible with MySQL protocal and MySQL SQL grama,underlying storage only support MySQL for support foreground business more simple,stable,efficient and safety。
说明:cobar的前身是amoeba;
网址
- cobar github
- cobar 官网 — 无
架构图
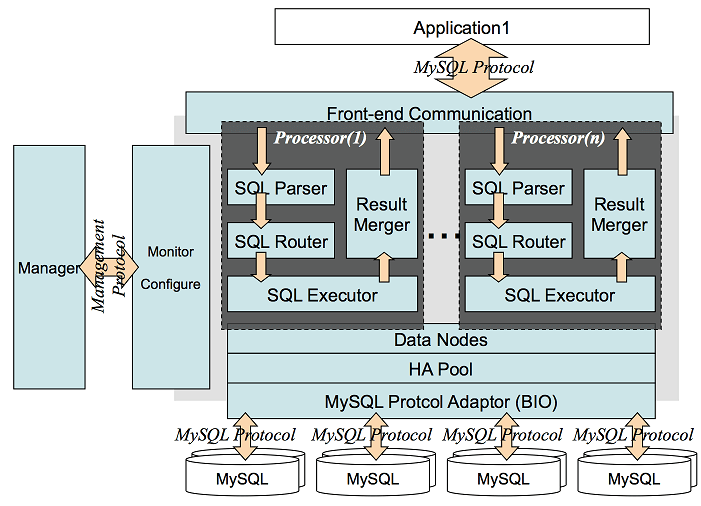

Cobar_architecture
特性
- 不支持跨库(数据节点)的关联操作:join、分页、排序、子查询。
- BLOB, BINARY, VARBINARY字段不能使用。若特殊需求需要这三种字段,禁止使用PreparedStatement的setBlob()或setBinaryStream()方法设置参数。
- 对于拆分表(分库表),不能更新已有记录的拆分字段(分库字段)值。
- 只支持MySQL数据节点,使用mysql-jdbc-5.1以上版本,推荐5.1.6或者5.1.12版本。
- 对于拆分表,插入操作须给出列名,必须包含拆分字段。
备注: cobar限制摘自cobar github
SQL优化示例
- select * from t_order where partition_key in(…)的优化(根据条件往目标服务器上发送SQL然后对返回的结果merge)
- select * from t_order where user_id=12 and article_id=10023的优化(两个字段作为拆分字段:X轴上user_id取模,Y轴上article_id取模)
- select * from t_order order by txn_time desc limit 100,2的优化(方式1:往所有服务器上发送limit 0, 102然后对返回的结果merge,如果偏移量太大,问题比较严重;方式2:假设各个分库数据分布大致一样… …)
- select sum(price) from t_order group by item_id的优化(往所有服务器上发送select sum(price), item_id from t_order group by item_id order by item_id然后对返回的结果merge)
cobar缺点
- SQL批处理模式采用SQL并发执行,所以事务会跨库,可能导致数据不一致;
- cobar前端后端之间的"写队列"可能导致阻塞,MyCAT将数据结构由数组改为链表,且达到指定阈值会产生告警日志;
- 部署双机cobar负载均衡前提下,可能出现主备两个库都在写数据;原因是cobar启动时默认第一个datasource进行数据读写操作;
- cobar连接池的缺陷,cobar连接池的管理基于分片,假设db-server1和db-server2上各50个分片,且连接池上限为1000,那么每个片只有20个连接在连接池中;各分片之间的连接池不互通,从而导致饥饱不均–db-server1上可用连接充足但是某分片连接耗尽;
- 不支持读写分离;
来源于MyCAT权威指南
2. MyCAT
MyCAT is an enforced database which is a replacement for MySQL and supports transaction and ACID. MyCAT is combined with the traditional database and new distributed data warehouse. In a word, MyCAT is a fresh new middleware of database. Mycat’s target is to smoothly migrate the current stand-alone database and applications to cloud side with low cost and to solve the bottleneck problem caused by the rapid growth of data storage and business scale.
说明:MyCAT的前身是cobar,1.4 版本以后 完全的脱离基本cobar内核;
网址
特性
- 遵守Mysql原生协议,跨语言,跨平台,跨数据库的通用中间件代理。
- 基于心跳的自动故障切换,支持读写分离,支持MySQL主从,以及galera cluster集群。
- 支持Galera for MySQL集群,Percona Cluster或者MariaDB cluster。
- 支持单库内部任意join,支持跨库2表join,甚至基于caltlet的多表join。
- 集群基于ZooKeeper管理,在线升级,扩容,智能优化,大数据处理(2.0开发版)。
- 支付多租户;
MyCAT特性来源于MyCAT官网
3. shardding-jdbc
Sharding-JDBC is a JDBC extension, provides distributed features such as sharding, read/write splitting, BASE transaction and database orchestration.
网址
架构图
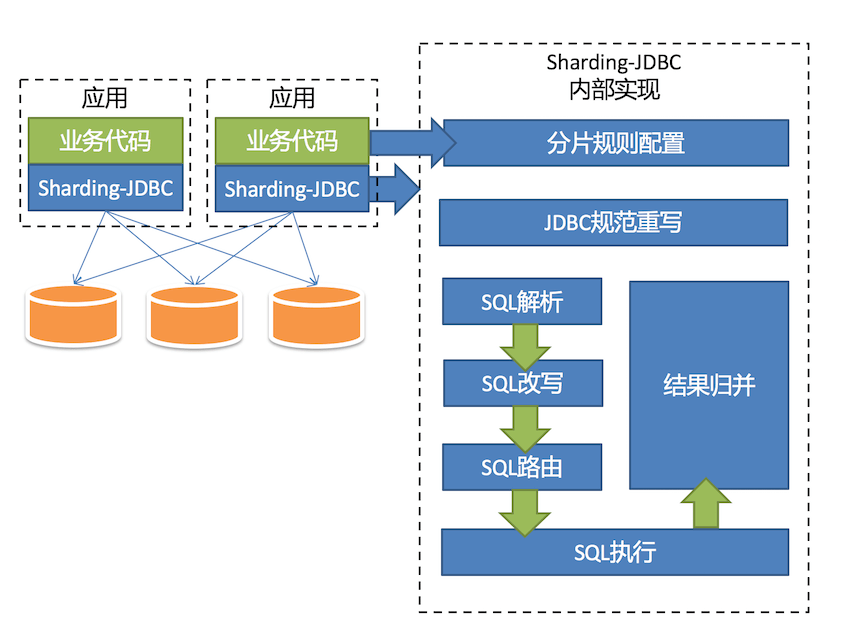
sharding-jdbc架构图
特性
- Aggregation functions, group by, order by and limit SQL supported in distributed database.
- Join (inner/outer) query supported.
- Sharding operator =, BETWEEN and IN supported.
- Sharding algorithm customization supported.
- Hint supported(强制主库路由).
- BASE Transaction(柔性事务–最大努力送达事务).
- Read/Write Splitting.
- Distributed Unique Time-Sequence Generation.
限制
- 不支持or;(1.5.x之前支持OR,1.5.x之后不再支持,原因是有or时SQL的解析和路由都非常复杂,某些or的SQL性能非常差不适合分布式数据库使用)
- 不支持HAVING
- 不支持UNION & UNION ALL
- 不支持DISTINCT聚合
- 不支持存储过程,函数,游标的操作
- 不支持执行native的SQL
- 不支持savepoint相关操作
- 不支持Schema/Catalog的操作
- 不支持自定义类型映射
sharding-jdbc限制来源于http://shardingjdbc.io/1.x/docs/01-start/limitations/
分库分表
- 支持多分片键
- 支持通过=,BETWEEN,IN分片
- 支持级联表
- 支持多表笛卡尔积查询
- 支持多表结果归并
- 支持聚合查询结果归并
- 支持AVG函数改写为SUM/COUNT
- 支持ORDER BY结果归并
- 支持GROUP BY结果归并
- 支持LIMIT分页查询以及多库表结果改写及归并
作者:阿飞的博客
来源:https://www.jianshu.com/p/5d7d5acc070e
看完两件小事
如果你觉得这篇文章对你挺有启发,我想请你帮我两个小忙:
- 把这篇文章分享给你的朋友 / 交流群,让更多的人看到,一起进步,一起成长!
- 关注公众号 「方志朋」,公众号后台回复「666」 免费领取我精心整理的进阶资源教程

 微信扫一扫
微信扫一扫