
第7篇:死磕 java集合之TreeMap源码分析(四)-内含彩蛋
欢迎关注我的公众号“彤哥读源码”,查看更多源码系列文章, 与彤哥一起畅游源码的海洋。
二叉树的遍历
我们知道二叉查找树的遍历有前序遍历、中序遍历、后序遍历。
(1)前序遍历,先遍历我,再遍历我的左子节点,最后遍历我的右子节点;
(2)中序遍历,先遍历我的左子节点,再遍历我,最后遍历我的右子节点;
(3)后序遍历,先遍历我的左子节点,再遍历我的右子节点,最后遍历我;
这里的前中后都是以“我”的顺序为准的,我在前就是前序遍历,我在中就是中序遍历,我在后就是后序遍历。
下面让我们看看经典的中序遍历是怎么实现的:
public class TreeMapTest {
public static void main(String[] args) {
// 构建一颗10个元素的树
TreeNode<Integer> node = new TreeNode<>(1, null).insert(2)
.insert(6).insert(3).insert(5).insert(9)
.insert(7).insert(8).insert(4).insert(10);
// 中序遍历,打印结果为1到10的顺序
node.root().inOrderTraverse();
}
}
/**
* 树节点,假设不存在重复元素
* @param <T>
*/
class TreeNode<T extends Comparable<T>> {
T value;
TreeNode<T> parent;
TreeNode<T> left, right;
public TreeNode(T value, TreeNode<T> parent) {
this.value = value;
this.parent = parent;
}
/**
* 获取根节点
*/
TreeNode<T> root() {
TreeNode<T> cur = this;
while (cur.parent != null) {
cur = cur.parent;
}
return cur;
}
/**
* 中序遍历
*/
void inOrderTraverse() {
if(this.left != null) this.left.inOrderTraverse();
System.out.println(this.value);
if(this.right != null) this.right.inOrderTraverse();
}
/**
* 经典的二叉树插入元素的方法
*/
TreeNode<T> insert(T value) {
// 先找根元素
TreeNode<T> cur = root();
TreeNode<T> p;
int dir;
// 寻找元素应该插入的位置
do {
p = cur;
if ((dir=value.compareTo(p.value)) < 0) {
cur = cur.left;
} else {
cur = cur.right;
}
} while (cur != null);
// 把元素放到找到的位置
if (dir < 0) {
p.left = new TreeNode<>(value, p);
return p.left;
} else {
p.right = new TreeNode<>(value, p);
return p.right;
}
}
}
TreeMap的遍历
从上面二叉树的遍历我们很明显地看到,它是通过递归的方式实现的,但是递归会占用额外的空间,直接到线程栈整个释放掉才会把方法中申请的变量销毁掉,所以当元素特别多的时候是一件很危险的事。
(上面的例子中,没有申请额外的空间,如果有声明变量,则可以理解为直到方法完成才会销毁变量)
那么,有没有什么方法不用递归呢?
让我们来看看java中的实现:
@Override
public void forEach(BiConsumer<? super K, ? super V> action) {
Objects.requireNonNull(action);
// 遍历前的修改次数
int expectedModCount = modCount;
// 执行遍历,先获取第一个元素的位置,再循环遍历后继节点
for (Entry<K, V> e = getFirstEntry(); e != null; e = successor(e)) {
// 执行动作
action.accept(e.key, e.value);
// 如果发现修改次数变了,则抛出异常
if (expectedModCount != modCount) {
throw new ConcurrentModificationException();
}
}
}
是不是很简单?!
(1)寻找第一个节点;
从根节点开始找最左边的节点,即最小的元素。
final Entry<K,V> getFirstEntry() {
Entry<K,V> p = root;
// 从根节点开始找最左边的节点,即最小的元素
if (p != null)
while (p.left != null)
p = p.left;
return p;
}
(2)循环遍历后继节点;
寻找后继节点这个方法我们在删除元素的时候也用到过,当时的场景是有右子树,则从其右子树中寻找最小的节点。
static <K,V> TreeMap.Entry<K,V> successor(Entry<K,V> t) {
if (t == null)
// 如果当前节点为空,返回空
return null;
else if (t.right != null) {
// 如果当前节点有右子树,取右子树中最小的节点
Entry<K,V> p = t.right;
while (p.left != null)
p = p.left;
return p;
} else {
// 如果当前节点没有右子树
// 如果当前节点是父节点的左子节点,直接返回父节点
// 如果当前节点是父节点的右子节点,一直往上找,直到找到一个祖先节点是其父节点的左子节点为止,返回这个祖先节点的父节点
Entry<K,V> p = t.parent;
Entry<K,V> ch = t;
while (p != null && ch == p.right) {
ch = p;
p = p.parent;
}
return p;
}
}
让我们一起来分析下这种方式的时间复杂度吧。
首先,寻找第一个元素,因为红黑树是接近平衡的二叉树,所以找最小的节点,相当于是从顶到底了,时间复杂度为O(log n);
其次,寻找后继节点,因为红黑树插入元素的时候会自动平衡,最坏的情况就是寻找右子树中最小的节点,时间复杂度为O(log k),k为右子树元素个数;
最后,需要遍历所有元素,时间复杂度为O(n);
所以,总的时间复杂度为 O(log n) + O(n * log k) ≈ O(n)。
虽然遍历红黑树的时间复杂度是O(n),但是它实际是要比跳表要慢一点的,啥?跳表是啥?安心,后面会讲到跳表的。
总结
到这里红黑树就整个讲完了,让我们再回顾下红黑树的特性:
(1)每个节点或者是黑色,或者是红色。
(2)根节点是黑色。
(3)每个叶子节点(NIL)是黑色。(注意:这里叶子节点,是指为空(NIL或NULL)的叶子节点!)
(4)如果一个节点是红色的,则它的子节点必须是黑色的。
(5)从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。
除了上述这些标准的红黑树的特性,你还能讲出来哪些TreeMap的特性呢?
(1)TreeMap的存储结构只有一颗红黑树;
(2)TreeMap中的元素是有序的,按key的顺序排列;
(3)TreeMap比HashMap要慢一些,因为HashMap前面还做了一层桶,寻找元素要快很多;
(4)TreeMap没有扩容的概念;
(5)TreeMap的遍历不是采用传统的递归式遍历;
(6)TreeMap可以按范围查找元素,查找最近的元素;
(7)欢迎补充…
带详细注释的源码地址
微信用户请“阅读原文”,进入仓库查看,其它渠道直接点击此链接即可跳转。
彩蛋
上面我们说到的删除元素的时候,如果当前节点有右子树,则从右子树中寻找最小元素所在的位置,把这个位置的元素放到当前位置,再把删除的位置移到那个位置,再看有没有替代元素,balabala。
那么,除了这种方式,还有没有其它方式呢?
答案当然是肯定的。
上面我们说的红黑树的插入元素、删除元素的过程都是标准的红黑树是那么干的,其实也不一定要完全那么做。
比如说,删除元素,如果当前节点有左子树,那么,我们可以找左子树中最大元素的位置,然后把这个位置的元素放到当前节点,再把删除的位置移到那个位置,再看有没有替代元素,balabala。
举例说明,比如下面这颗红黑树:
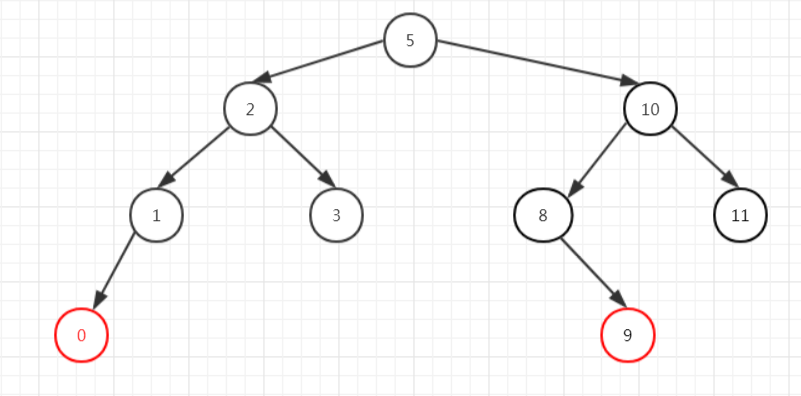

我们删除10这个元素,从左子树中找最大的,找到了9这个元素,那么把9放到10的位置,然后把删除的位置移到原来9的位置,发现不需要作平衡(红+黑节点),直接把这个位置删除就可以了。
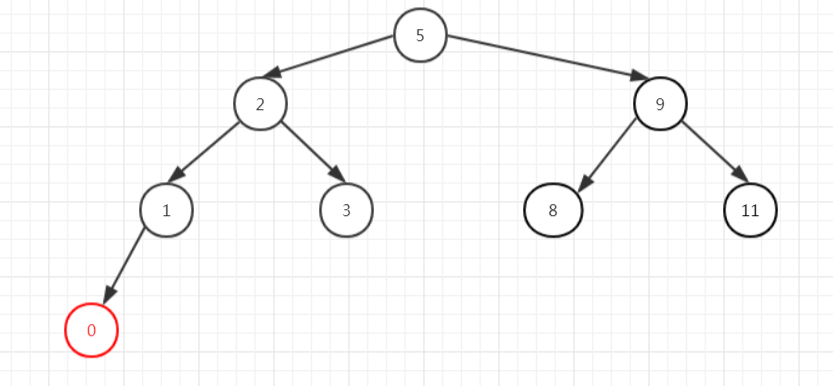
同样是满足红黑树的特性的。
所以,死读书不如无书,学习的过程也是一个不断重塑知识的过程。
作者:彤哥读源码
来源:https://www.cnblogs.com/tong-yuan/p/10657637.html
看完两件小事
如果你觉得这篇文章对你挺有启发,我想请你帮我两个小忙:
- 把这篇文章分享给你的朋友 / 交流群,让更多的人看到,一起进步,一起成长!
- 关注公众号 「方志朋」,公众号后台回复「666」 免费领取我精心整理的进阶资源教程

本文著作权归作者所有,如若转载,请注明出处
转载请注明:文章转载自「 Java极客技术学习 」https://www.javajike.com
 微信扫一扫
微信扫一扫