
Java基础:Java容器之LinkedList
Java容器之LinkedList
定义
实现List接口与Deque接口双向链表,实现了列表的所有操作,并且允许包括null值的所有元素,对于LinkedList定义我产生了如下疑问:
- 1.Deque接口是什么,定义了一个怎样的规范?
- 2.LinkedList是双向链表,其底层实现是怎样的,具体包含哪些操作?
下文将围绕这两个问题进行,去探寻LinkedList内部的奥秘,以下源码是基于JDK1.7.0_79。
结构
类结构
LinkedList的类的结构如下图所示:
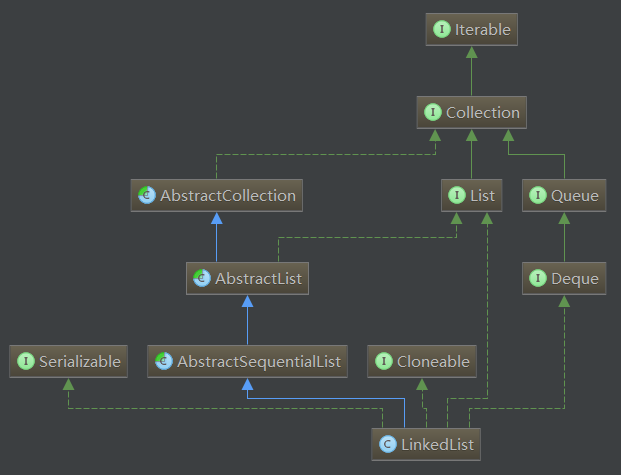

通过上图可以看出,LinkedList继承的类与实现的接口如下:
1.Collection 接口: Collection接口是所有集合类的根节点,Collection表示一种规则,所有实现了Collection接口的类遵循这种规则2.List 接口: List是Collection的子接口,它是一个元素有序(按照插入的顺序维护元素顺序)、可重复、可以为null的集合3.AbstractCollection 类: Collection接口的骨架实现类,最小化实现了Collection接口所需要实现的工作量4.AbstractList 类: List接口的骨架实现类,最小化实现了List接口所需要实现的工作量5.Cloneable 接口: 实现了该接口的类可以显示的调用Object.clone()方法,合法的对该类实例进行字段复制,如果没有实现Cloneable接口的实例上调用Obejct.clone()方法,会抛出CloneNotSupportException异常。正常情况下,实现了Cloneable接口的类会以公共方法重写Object.clone()6.Serializable 接口: 实现了该接口标示了类可以被序列化和反序列化,具体的 查询序列化详解7.Deque 接口: Deque定义了一个线性Collection,支持在两端插入和删除元素,Deque实际是“double ended queue(双端队列)”的简称,大多数Deque接口的实现都不会限制元素的数量,但是这个队列既支持有容量限制的实现,也支持没有容量限制的实现,比如LinkedList就是有容量限制的实现,其最大的容量为Integer.MAX_VALUE8.AbstractSequentialList 类: 提供了List接口的骨干实现,最大限度地减少了实现受“连续访问”数据存储(如链表)支持的此接口所需的工作,对于随机访问数据(如数组),应该优先使用 AbstractList,而不是使用AbstractSequentailList类
基础属性及构造方法
基础属性
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
//长度
transient int size = 0;
//指向头结点
transient Node<E> first;
//指向尾结点
transient Node<E> last;
}
如上源码中为LinkedList中的基本属性,其中size为LinkedList的长度,first为指向头结点,last指向尾结点,Node为LinkedList的一个私有内部类,其定义如下,即定义了item(元素),next(指向后一个元素的指针),prev(指向前一个元素的指针)
private static class Node<E> {
//元素
E item;
//指向后一个元素的指针
Node<E> next;
//指向前一个元素的指针
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
那么假如LinkedList中的元素为["A","B","C"],其内部的结构如下图所示
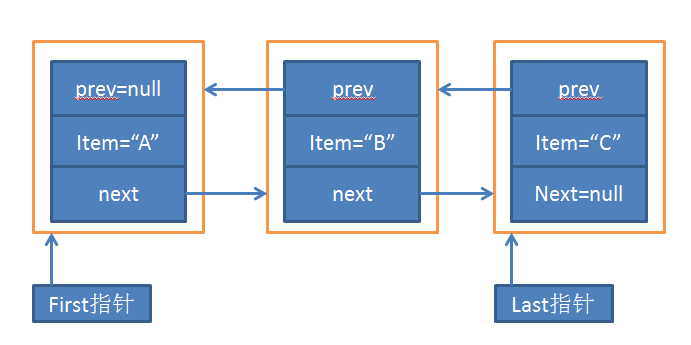
可以看出一个节点中包含三个属性,也就是上面源码中定义的属性,可以清晰的看出LinkedList底层是双向链表的实现
构造方法
在源码中,LinkedList主要提供了两个构造方法,
- 1.public LinkedList() :空的构造方法,啥事情都没有做
- 2.public LinkedList(Collection<? extends E> c) : 将一个元素集合添加到LinkedList中
底层实现
在2.2.1中的LinkedList内部结构图,可以清晰的看出LinkedList双向链表的实现,下面将通过源码分析如何在双向链表中添加和删除节点的。
添加节点
通常我们会使用add(E e)方法添加元素,通过源码我们发现add(E e)内部主要调用了以下方法
//在链表的最后添加元素
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
其实通过源码可以看出添加的过程如下
- 1.记录当前末尾节点,通过构造另外一个指向末尾节点的指针l
- 2.产生新的节点:注意的是由于是添加在链表的末尾,next是为null的
- 3.last指向新的节点
- 4.这里有个判断,我的理解是判断是否为第一个元素(当l==null时,表示链表中是没有节点的),
那么就很好理解这个判断了,如果是第一节点,则使用first指向这个节点,若不是则当前节点的next指向新增的节点 - 5.size增加
例如,在上面提到的LinkedList["A","B","C"]中添加元素“D”,过程大致如图所示
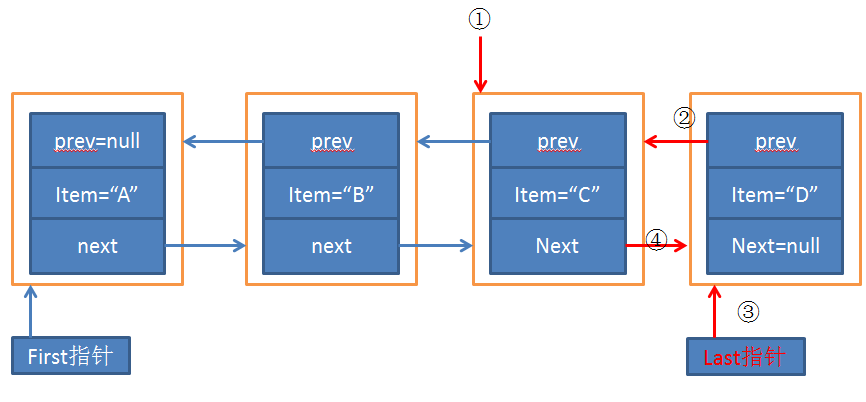
LinkedList中还提供如下的方法,进行添加元素,具体逻辑与linkLast方法大同小异,就不在这里一一介绍了。
删除节点
LinkedList中提供了两个方法删除节点,如下源码所示
//方法1.删除指定索引上的节点
public E remove(int index) {
//检查索引是否正确
checkElementIndex(index);
//这里分为两步,第一通过索引定位到节点,第二删除节点
return unlink(node(index));
}
//方法2.删除指定值的节点
public boolean remove(Object o) {
//判断删除的元素是否为null
if (o == null) {
//若是null遍历删除
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
//若不是遍历删除
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
通过源码可以看出两个方法都是通过unlink()删除,在方法一种有个方法要介绍下,就是node(index)该方法的作用就是根据下标找到对应的节点,要是本人去写这个方法肯定是遍历到index找到对应的节点,而JDK提供的方法如下所示
- 1.首先确定index的位置,是靠近first还是靠近last
- 2.若靠近first则从头开始查询,否则从尾部开始查询,可以看出这样避免极端情况的发生,也更好的利用了LinkedList双向链表的特征
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
下面会详细介绍unlink()方法的源码,这是删除节点最核心的方法
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
//删除的是第一个节点,first向后移动
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
//删除的是最后一个节点,last向前移
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
- 1.获取到需要删除元素当前的值,指向它前一个节点的引用,以及指向它后一个节点的引用。
- 2.判断删除的是否为第一个节点,若是则first向后移动,若不是则将当前节点的前一个节点next指向当前节点的后一个节点
- 3.判断删除的是否为最后一个节点,若是则last向前移动,若不是则将当前节点的后一个节点的prev指向当前节点的前一个节点
- 4.将当前节点的值置为null
- 5.size减少并返回删除节点的值
至此介绍了LinkedList添加、删除元素的内部实现。
4.对比
在ArrList详解中讲解了ArrayList的相关的内容,下面将对ArrayList与LinkedList进行对比,主要从以下方面进行
4.1 相同点
- 1.接口实现:都实现了List接口,都是线性列表的实现
- 2.线程安全:都是线程不安全的
4.2 区别
- 1.底层实现:ArrayList内部是数组实现,而LinkedList内部实现是双向链表结构
- 2.接口实现:ArrayList实现了RandomAccess可以支持随机元素访问,而LinkedList实现了Deque可以当做队列使用
- 3.性能:新增、删除元素时ArrayList需要使用到拷贝原数组,而LinkedList只需移动指针,查找元素 ArrayList支持随机元素访问,而LinkedList只能一个节点的去遍历
4.3 性能比较
下面通过代码去比较下ArrayList与LinkedList在性能方面的差别,代码如下
public class ListPerformance {
private static ArrayList<String> arrayList= new ArrayList<String>();
private static LinkedList<String> linkedList = new LinkedList<String>();
/**
* 插入数据
* @param list
* @param count
*/
public static void insertElements(List<String> list, int count){
Long startTime = System.currentTimeMillis();
for (int i = 0; i < count; i++) {
list.add(String.valueOf(i));
}
Long endTime = System.currentTimeMillis();
System.out.println("insert elements use time: " +(endTime-startTime) + " ms");
}
/**
* 删除元素
* @param list
* @param count
*/
public static void removeElements(List<String> list, int count){
Long startTime = System.currentTimeMillis();
for (int i = 0; i < count; i++) {
list.remove(0);
}
Long endTime = System.currentTimeMillis();
System.out.println("remove elements use time: " +(endTime-startTime) + " ms");
}
/**
* 获取元素
* @param list
* @param count
*/
public static void getElements(List<String> list, int count){
Long startTime = System.currentTimeMillis();
for (int i = 0; i < count; i++) {
list.get(i);
}
Long endTime = System.currentTimeMillis();
System.out.println("get elements use time: " +(endTime-startTime) + " ms");
}
/**
* 删除元素第二种实现
* @param list
* @param count
*/
public static void removeElements2(List<String> list, int count){
Long startTime = System.currentTimeMillis();
for (int i = count-1; i > 0; i--) {
list.remove(i);
}
Long endTime = System.currentTimeMillis();
System.out.println("remove elements use time: " +(endTime-startTime) + " ms");
}
public static void main(String[] args){
System.out.println("arrayList test");
insertElements(arrayList,100000);
getElements(arrayList,100000);
removeElements(arrayList,100000);
System.out.println("linkedList test");
insertElements(linkedList,100000);
getElements(linkedList,100000);
removeElements(linkedList,100000);
System.out.println("arrayList test2");
insertElements(arrayList,100000);
getElements(arrayList,100000);
removeElements2(arrayList,100000);
System.out.println("linkedList test2");
insertElements(linkedList,100000);
getElements(linkedList,100000);
removeElements2(linkedList,100000);
}
结果如下图所示,可以看出
- 1.LinkedList下插入、删除是性能优于ArrayList,这是由于插入、删除元素时ArrayList中需要额外的开销去移动、拷贝元素(但是使用removeElements2方法所示去遍历删除是速度异常的快,这种方式的做法是从末尾开始删除,不存在移动、拷贝元素,从而速度非常快)
- 2.ArrayList在查询元素的性能上要由于LinkedList
自己动手写个LinkedList
自己动手实现一个这样的LinkedList:
public class MyLinkList<T> implements Iterable<T> {
private int size;
private int modeCount = 0;
private Node<T> beginMarker;
private Node<T> endMarker;
public MyLinkList() {
doClear();
}
private void doClear() {
size = 0;
modeCount++;
beginMarker = new Node<T>(null, null, null);
endMarker = new Node<T>(null, beginMarker, null);
beginMarker.next = endMarker;
}
public boolean add(T data) {
Node<T> node = new Node<>(data, endMarker.prev, endMarker);
endMarker.prev.next = node;
endMarker.prev = node;
modeCount++;
size++;
return true;
}
public T remove(int index) {
Node<T> node = getNode(index);
node.prev.next = node.next;
node.next.prev = node.prev;
size--;
modeCount--;
return node.data;
}
public Node<T> getNode(int index) {
Node<T> p;
if (index < 0 | index >= size) {
throw new IndexOutOfBoundsException("out of index");
}
if (index < size / 2) {//从左边开始找
p = beginMarker.next;
for (int i = 0; i < index; i++) {
p = p.next;
}
} else {//从右边开始找
p = endMarker;
for (int i = size; i > index; i--) {
p = p.prev;
}
}
return p;
}
public T get(int index) {
return getNode(index).data;
}
@Override
public Iterator<T> iterator() {
return null;
}
@Override
public void forEach(Consumer<? super T> action) {
}
@Override
public Spliterator<T> spliterator() {
return null;
}
static class Node<T> {
private T data;
private Node<T> prev;
private Node<T> next;
public Node(T data, Node<T> prev, Node<T> next) {
this.data = data;
this.prev = prev;
this.next = next;
}
}
}
参考文章
https://www.jianshu.com/p/732b5294a985
看完两件小事
如果你觉得这篇文章对你挺有启发,我想请你帮我两个小忙:
- 把这篇文章分享给你的朋友 / 交流群,让更多的人看到,一起进步,一起成长!
- 关注公众号 「方志朋」,公众号后台回复「666」 免费领取我精心整理的进阶资源教程

本文著作权归作者所有,如若转载,请注明出处
转载请注明:文章转载自「 Java极客技术学习 」https://www.javajike.com
 微信扫一扫
微信扫一扫 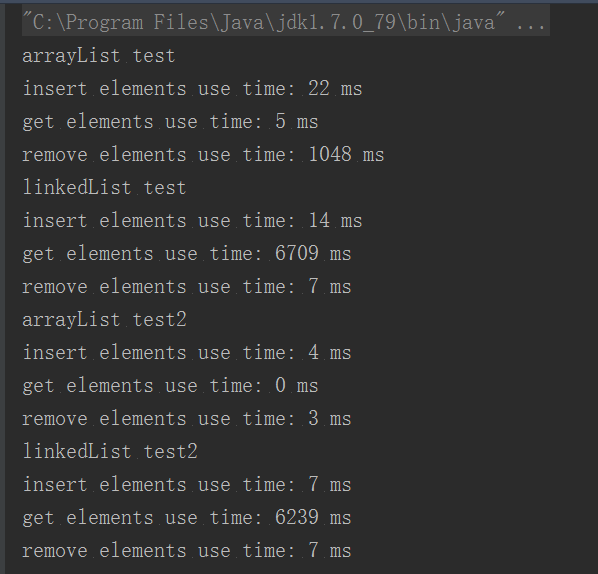{kind=link}