
005-五、GC 性能优化 – GC 算法(实现篇)
除了对作者表示感谢外,还需要感谢译者【铁锚】,谢谢两位的付出
出处:https://blog.csdn.net/renfufei/column/info/14851
学习了GC算法的相关概念之后, 我们将介绍在 JVM 中这些算法的具体实现。首先要记住的是, 大多数 JVM 都需要使用两种不同的 GC 算法 —— 一种用来清理年轻代, 另一种用来清理老年代。
我们可以选择 JVM 内置的各种算法。如果不通过参数明确指定垃圾收集算法, 则会使用宿主平台的默认实现。本章会详细介绍各种算法的实现原理。
下面是关于Java 8中各种组合的垃圾收集器概要列表,对于之前的 Java 版本来说,可用组合会有一些不同:
| Young | Tenured | JVMoptions |
|---|---|---|
| Young | Tenured | JVMoptions |
| Incremental(增量GC) | Incremental | -Xincgc |
| Serial | Serial | -XX:+UseSerialGC |
| ParallelScavenge | Serial | -XX:+UseParallelGC-XX:-UseParallelOldGC |
| ParallelNew | Serial | N/A |
| Serial | ParallelOld | N/A |
| ParallelScavenge | ParallelOld | -XX:+UseParallelGC-XX:+UseParallelOldGC |
| ParallelNew | ParallelOld | N/A |
| Serial | CMS | -XX:-UseParNewGC-XX:+UseConcMarkSweepGC |
| ParallelScavenge | CMS | N/A |
| ParallelNew | CMS | -XX:+UseParNewGC-XX:+UseConcMarkSweepGC |
| G1 | -XX:+UseG1GC |
看起来有些复杂, 不用担心。主要使用的是上表中黑体字表示的这四种组合。其余的要么是[被废弃(deprecated)](http://openjdk.java.net/jeps/173 "被废弃(deprecated)"), 要么是不支持或者是不太适用于生产环境。所以,接下来我们只介绍下面这些组合及其工作原理:
- 年轻代和老年代的串行
GC(Serial GC) - 年轻代和老年代的并行
GC(Parallel GC) - 年轻代的并行
GC(Parallel New)+ 老年代的CMS(Concurrent Mark and Sweep) G1, 负责回收年轻代和老年代
Serial GC(串行GC)
Serial GC 对年轻代使用 mark-copy(标记-复制) 算法, 对老年代使用 mark-sweep-compact(标记-清除-整理)算法. 顾名思义, 两者都是单线程的垃圾收集器,不能进行并行处理。两者都会触发全线暂停(STW),停止所有的应用线程。
因此这种 GC 算法不能充分利用多核 CPU。不管有多少 CPU 内核, JVM 在垃圾收集时都只能使用单个核心。
要启用此款收集器, 只需要指定一个 JVM 启动参数即可,同时对年轻代和老年代生效:
java -XX:+UseSerialGC com.mypackages.MyExecutableClass
该选项只适合几百 MB 堆内存的 JVM,而且是单核 CPU 时比较有用。 对于服务器端来说, 因为一般是多个 CPU 内核, 并不推荐使用, 除非确实需要限制JVM所使用的资源。大多数服务器端应用部署在多核平台上, 选择 Serial GC 就表示人为的限制系统资源的使用。 导致的就是资源闲置, 多的 CPU 资源也不能用来降低延迟,也不能用来增加吞吐量。
下面让我们看看 Serial GC 的垃圾收集日志, 并从中提取什么有用的信息。为了打开 GC 日志记录, 我们使用下面的JVM启动参数:
-XX:+PrintGCDetails -XX:+PrintGCDateStamps
-XX:+PrintGCTimeStamps
产生的 GC 日志输出类似这样(为了排版,已手工折行):
-05-26T14:45:37.987-0200:
151.126: [GC (Allocation Failure)
151.126: [DefNew: 629119K->69888K(629120K), 0.0584157 secs]
1619346K->1273247K(2027264K), 0.0585007 secs]
[Times: user=0.06 sys=0.00, real=0.06 secs]
-05-26T14:45:59.690-0200:
172.829: [GC (Allocation Failure)
172.829: [DefNew: 629120K->629120K(629120K), 0.0000372 secs]
172.829: [Tenured: 1203359K->755802K(1398144K), 0.1855567 secs]
1832479K->755802K(2027264K),
[Metaspace: 6741K->6741K(1056768K)], 0.1856954 secs]
[Times: user=0.18 sys=0.00, real=0.18 secs]
此 GC 日志片段展示了在 JVM 中发生的很多事情。 实际上,在这段日志中产生了两个 GC 事件, 其中一次清理的是年轻代,另一次清理的是整个堆内存。让我们先来分析前一次 GC,其在年轻代中产生。
Minor GC(小型GC)
以下代码片段展示了清理年轻代内存的GC事件:
-05-26T14:45:37.987-02001 : 151.12622 : [ GC3 (Allocation Failure4 151.126:
[DefNew5 : 629119K->69888K6 (629120K)7 , 0.0584157 secs] 1619346K->1273247K8
(2027264K)9, 0.0585007 secs10] [Times: user=0.06 sys=0.00, real=0.06 secs]11
1、 2015-05-26T14:45:37.987-0200 – GC事件开始的时间. 其中-0200表示西二时区,而中国所在的东8区为 +0800。
2、 151.126 – GC事件开始时,相对于JVM启动时的间隔时间,单位是秒。
3、 GC – 用来区分 Minor GC 还是 Full GC 的标志。GC表明这是一次小型GC(Minor GC)
4、 Allocation Failure – 触发 GC 的原因。本次GC事件, 是由于年轻代中没有空间来存放新的数据结构引起的。
5、 DefNew – 垃圾收集器的名称。这个神秘的名字表示的是在年轻代中使用的: 单线程, 标记-复制(mark-copy), 全线暂停(STW) 垃圾收集器。
6、 629119K->69888K – 在垃圾收集之前和之后年轻代的使用量。
7、 (629120K) – 年轻代总的空间大小。
8、 1619346K->1273247K – 在垃圾收集之前和之后整个堆内存的使用情况。
9、 (2027264K) – 可用堆的总空间大小。
10、 0.0585007 secs – GC事件持续的时间,以秒为单位。
11、 [Times: user=0.06 sys=0.00, real=0.06 secs] – GC事件的持续时间, 通过三个部分来衡量:
user– 在此次垃圾回收过程中, 所有 GC线程所消耗的CPU时间之和。sys–GC过程中中操作系统调用和系统等待事件所消耗的时间。real– 应用程序暂停的时间。因为串行垃圾收集器(SerialGarbageCollector)只使用单线程, 因此realtime等于user和system时间的总和。
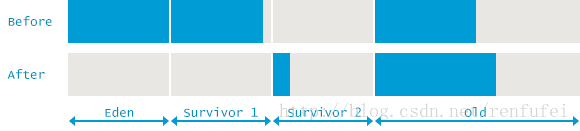
可以从上面的日志片段了解到, 在GC事件中,JVM的内存使用情况发生了怎样的变化。此次垃圾收集之前, 堆内存总的使用量为1,619,346K。其中,年轻代使用了629,119K。可以算出,老年代使用量为990,227K。
更重要的信息蕴含在下一批数字中, 垃圾收集之后, 年轻代的使用量减少了559,231K, 但堆内存的总体使用量只下降了 346,099K。 从中可以算出,有 213,132K 的对象从年轻代提升到了老年代。
此次 GC 事件也可以用下面的示意图来说明, 显示的是 GC 开始之前, 以及刚刚结束之后, 这两个时间点内存使用情况的快照:

Full GC(完全GC)
理解第一次 minor GC 事件后,让我们看看日志中的第二次 GC 事件:
-05-26T14:45:59.690-02001 : 172.8292 : [GC (Allocation Failure 172.829:
[DefNew: 629120K->629120K(629120K), 0.0000372 secs3] 172.829:[Tenured4:
K->755802K5 (1398144K)6, 0.1855567 secs7 ] 1832479K->755802K8
(2027264K)9, [Metaspace: 6741K->6741K(1056768K)]10
[Times: user=0.18 sys=0.00, real=0.18 secs]11
1、
2015-05-26T14:45:59.690-0200 – GC事件开始的时间. 其中-0200表示西二时区,而中国所在的东8区为 +0800。
2、172.829– GC事件开始时,相对于JVM启动时的间隔时间,单位是秒。
3、 [DefNew: 629120K->629120K(629120K), 0.0000372 secs– 与上面的示例类似, 因为内存分配失败,在年轻代中发生了一次minor GC。此次GC同样使用的是DefNew收集器, 让年轻代的使用量从629120K降为0。注意,JVM对此次GC的报告有些问题,误将年轻代认为是完全填满的。此次垃圾收集消耗了0.0000372秒。
4、Tenured– 用于清理老年代空间的垃圾收集器名称。Tenured 表明使用的是单线程的全线暂停垃圾收集器, 收集算法为 标记-清除-整理(mark-sweep-compact)。
5、1203359K->755802K– 在垃圾收集之前和之后老年代的使用量。
6、(1398144K)– 老年代的总空间大小。
7、0.1855567 secs– 清理老年代所花的时间。
8、1832479K->755802K– 在垃圾收集之前和之后,整个堆内存的使用情况。
9、(2027264K)– 可用堆的总空间大小。
10、[Metaspace: 6741K->6741K(1056768K)]– 关于Metaspace空间, 同样的信息。可以看出, 此次GC过程中Metaspace中没有收集到任何垃圾。
11、 [Times: user=0.18 sys=0.00, real=0.18 secs] –GC事件的持续时间, 通过三个部分来衡量:
*user– 在此次垃圾回收过程中, 所有 GC线程所消耗的CPU时间之和。
*sys– GC过程中中操作系统调用和系统等待事件所消耗的时间。
*real– 应用程序暂停的时间。因为串行垃圾收集器(SerialGarbageCollector)只使用单线程, 因此realtime等于user和system时间的总和。
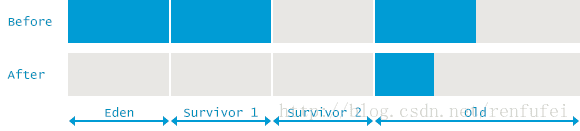
和 Minor GC 相比,最明显的区别是 —— 在此次GC事件中, 除了年轻代, 还清理了老年代和Metaspace. 在GC事件开始之前, 以及刚刚结束之后的内存布局,可以用下面的示意图来说明:
Parallel GC(并行GC)
并行垃圾收集器这一类组合, 在年轻代使用 标记-复制(mark-copy)算法, 在老年代使用 标记-清除-整理(mark-sweep-compact)算法。年轻代和老年代的垃圾回收都会触发STW事件,暂停所有的应用线程来执行垃圾收集。两者在执行 标记和 复制/整理阶段时都使用多个线程, 因此得名“(Parallel)”。通过并行执行, 使得GC时间大幅减少。
通过命令行参数 -XX:ParallelGCThreads=NNN 来指定 GC 线程数。 其默认值为CPU内核数。
可以通过下面的任意一组命令行参数来指定并行GC:
java -XX:+UseParallelGC com.mypackages.MyExecutableClass
java -XX:+UseParallelOldGC com.mypackages.MyExecutableClass
java -XX:+UseParallelGC -XX:+UseParallelOldGC com.mypackages.MyExecutableClass
并行垃圾收集器适用于多核服务器,主要目标是增加吞吐量。因为对系统资源的有效使用,能达到更高的吞吐量:
在GC期间, 所有 CPU 内核都在并行清理垃圾, 所以暂停时间更短
在两次GC周期的间隔期, 没有 GC 线程在运行,不会消耗任何系统资源
另一方面, 因为此GC的所有阶段都不能中断, 所以并行GC很容易出现长时间的停顿. 如果延迟是系统的主要目标, 那么就应该选择其他垃圾收集器组合。
译者注: 长时间卡顿的意思是,此 GC 启动之后,属于一次性完成所有操作, 于是单次 pause 的时间会较长。
让我们看看并行垃圾收集器的GC日志长什么样, 从中我们可以得到哪些有用信息。下面的GC日志中显示了一次 minor GC 暂停 和一次 major GC 暂停:
-05-26T14:27:40.915-0200: 116.115: [GC (Allocation Failure)
[PSYoungGen: 2694440K->1305132K(2796544K)]
9556775K->8438926K(11185152K)
, 0.2406675 secs]
[Times: user=1.77 sys=0.01, real=0.24 secs]
-05-26T14:27:41.155-0200: 116.356: [Full GC (Ergonomics)
[PSYoungGen: 1305132K->0K(2796544K)]
[ParOldGen: 7133794K->6597672K(8388608K)] 8438926K->6597672K(11185152K),
[Metaspace: 6745K->6745K(1056768K)]
, 0.9158801 secs]
[Times: user=4.49 sys=0.64, real=0.92 secs]
Minor GC(小型GC)
第一次GC事件表示发生在年轻代的垃圾收集:
-05-26T14:27:40.915-02001: 116.1152: [ GC3 (Allocation Failure4)
[PSYoungGen5: 2694440K->1305132K6 (2796544K)7] 9556775K->8438926K8
(11185152K)9, 0.2406675 secs10]
[Times: user=1.77 sys=0.01, real=0.24 secs]11
1、 2015-05-26T14:27:40.915-0200 – GC事件开始的时间. 其中-0200表示西二时区,而中国所在的东8区为 +0800。
2、 116.115 – GC事件开始时,相对于JVM启动时的间隔时间,单位是秒。
3、 GC – 用来区分 Minor GC 还是 Full GC 的标志。GC表明这是一次小型GC(Minor GC)
4、 Allocation Failure – 触发垃圾收集的原因。本次GC事件, 是由于年轻代中没有适当的空间存放新的数据结构引起的。
5、 PSYoungGen – 垃圾收集器的名称。这个名字表示的是在年轻代中使用的: 并行的 标记-复制(mark-copy), 全线暂停(STW) 垃圾收集器。
6、 2694440K->1305132K – 在垃圾收集之前和之后的年轻代使用量。
7、 (2796544K) – 年轻代的总大小。
8、 9556775K->8438926K – 在垃圾收集之前和之后整个堆内存的使用量。
9、 (11185152K) – 可用堆的总大小。
10. 0.2406675 secs – GC事件持续的时间,以秒为单位。
11. [Times: user=1.77 sys=0.01, real=0.24 secs] – GC事件的持续时间, 通过三个部分来衡量:
user – 在此次垃圾回收过程中, 由GC线程所消耗的总的CPU时间。
sys – GC过程中中操作系统调用和系统等待事件所消耗的时间。
real – 应用程序暂停的时间。在 Parallel GC 中, 这个数字约等于:(user time + system time)/GC线程数。 这里使用了8个线程。 请注意,总有一定比例的处理过程是不能并行进行的。
所以,可以简单地算出, 在垃圾收集之前, 堆内存总使用量为 9,556,775K。 其中年轻代为 2,694,440K。
同时算出老年代使用量为 6,862,335K. 在垃圾收集之后, 年轻代使用量减少为 1,389,308K, 但总的堆内存使用量只减少了 1,117,849K。这表示有大小为271,459K 的对象从年轻代提升到老年代。
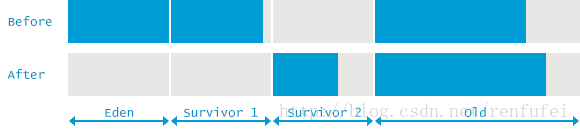
Full GC(完全GC)
学习了并行GC如何清理年轻代之后, 下面介绍清理整个堆内存的GC日志以及如何进行分析:
-05-26T14:27:41.155-0200 : 116.356 : [Full GC (Ergonomics)
[PSYoungGen: 1305132K->0K(2796544K)] [ParOldGen :7133794K->6597672K
(8388608K)] 8438926K->6597672K (11185152K),
[Metaspace: 6745K->6745K(1056768K)], 0.9158801 secs,
[Times: user=4.49 sys=0.64, real=0.92 secs]
1、
2015-05-26T14:27:41.155-0200 – GC事件开始的时间.其中-0200表示西二时区,而中国所在的东8区为+0800。
2、116.356 – GC事件开始时,相对于JVM启动时的间隔时间,单位是秒。 我们可以看到, 此次事件在前一次MinorGC完成之后立刻就开始了。
3、Full GC– 用来表示此次是Full GC的标志。Full GC表明本次清理的是年轻代和老年代。
4、Ergonomics– 触发垃圾收集的原因。Ergonomics表示JVM内部环境认为此时可以进行一次垃圾收集。
5、[PSYoungGen: 1305132K->0K(2796544K)]– 和上面的示例一样, 清理年轻代的垃圾收集器是名为 “PSYoungGen” 的STW收集器, 采用标记-复制(mark-copy)算法。 年轻代使用量从1305132K变为0, 一般Full GC的结果都是这样。
6、ParOldGen– 用于清理老年代空间的垃圾收集器类型。在这里使用的是名为ParOldGen的垃圾收集器, 这是一款并行 STW垃圾收集器, 算法为 标记-清除-整理(mark-sweep-compact)。
7、7133794K->6597672K– 在垃圾收集之前和之后老年代内存的使用情况。
8、(8388608K)– 老年代的总空间大小。
9、8438926K->6597672K– 在垃圾收集之前和之后堆内存的使用情况。
10.(11185152K)– 可用堆内存的总容量。
11.[Metaspace: 6745K->6745K(1056768K)]– 类似的信息,关于Metaspace空间的。可以看出, 在GC事件中Metaspace里面没有回收任何对象。
12.0.9158801 secs – GC事件持续的时间,以秒为单位。
13.[Times: user=4.49 sys=0.64, real=0.92 secs] – GC事件的持续时间, 通过三个部分来衡量:
user – 在此次垃圾回收过程中, 由GC线程所消耗的总的CPU时间。
sys – GC过程中中操作系统调用和系统等待事件所消耗的时间。
“real – 应用程序暂停的时间。在 Parallel GC 中, 这个数字约等于: (user time + system time)/GC线程数。 这里使用了8个线程。 请注意,总有一定比例的处理过程是不能并行进行的。
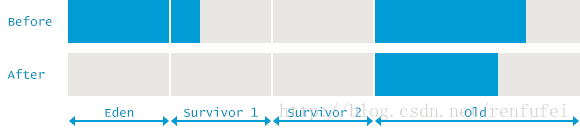
同样,和 Minor GC的区别是很明显的 —— 在此次GC事件中, 除了年轻代, 还清理了老年代和 Metaspace. 在GC事件前后的内存布局如下图所示:
Concurrent Mark and Sweep(并发标记-清除)
CMS 的官方名称为 “Mostly Concurrent Mark and Sweep Garbage Collector”(主要并发-标记-清除-垃圾收集器). 其对年轻代采用并行 STW 方式的 mark-copy (标记-复制)算法, 对老年代主要使用并发 mark-sweep (标记-清除)算法。
CMS 的设计目标是避免在老年代垃圾收集时出现长时间的卡顿。主要通过两种手段来达成此目标。
第一, 不对老年代进行整理, 而是使用空闲列表(free-lists)来管理内存空间的回收。
第二, 在 mark-and-sweep (标记-清除) 阶段的大部分工作和应用线程一起并发执行。
也就是说, 在这些阶段并没有明显的应用线程暂停。但值得注意的是, 它仍然和应用线程争抢 CPU 时间。默认情况下, CMS 使用的并发线程数等于 CPU 内核数的 1/4。
通过以下选项来指定 CMS 垃圾收集器:
java -XX:+UseConcMarkSweepGC com.mypackages.MyExecutableClass
如果服务器是多核 CPU,并且主要调优目标是降低延迟, 那么使用 CMS 是个很明智的选择. 减少每一次 GC 停顿的时间,会直接影响到终端用户对系统的体验, 用户会认为系统非常灵敏。
因为多数时候都有部分 CPU 资源被 GC 消耗, 所以在 CPU 资源受限的情况下,CMS 会比并行 GC 的吞吐量差一些。
和前面的GC算法一样, 我们先来看看CMS算法在实际应用中的GC日志, 其中包括一次 minor GC, 以及一次 major GC 停顿:
-05-26T16:23:07.219-0200: 64.322: [GC (Allocation Failure) 64.322:
[ParNew: 613404K->68068K(613440K), 0.1020465 secs]
10885349K->10880154K(12514816K), 0.1021309 secs]
[Times: user=0.78 sys=0.01, real=0.11 secs]
-05-26T16:23:07.321-0200: 64.425: [GC (CMS Initial Mark)
[1 CMS-initial-mark: 10812086K(11901376K)]
10887844K(12514816K), 0.0001997 secs]
[Times: user=0.00 sys=0.00, real=0.00 secs]
-05-26T16:23:07.321-0200: 64.425: [CMS-concurrent-mark-start]
-05-26T16:23:07.357-0200: 64.460: [CMS-concurrent-mark: 0.035/0.035 secs]
[Times: user=0.07 sys=0.00, real=0.03 secs]
-05-26T16:23:07.357-0200: 64.460: [CMS-concurrent-preclean-start]
-05-26T16:23:07.373-0200: 64.476: [CMS-concurrent-preclean: 0.016/0.016 secs]
[Times: user=0.02 sys=0.00, real=0.02 secs]
-05-26T16:23:07.373-0200: 64.476: [CMS-concurrent-abortable-preclean-start]
-05-26T16:23:08.446-0200: 65.550: [CMS-concurrent-abortable-preclean: 0.167/1.074 secs]
[Times: user=0.20 sys=0.00, real=1.07 secs]
-05-26T16:23:08.447-0200: 65.550: [GC (CMS Final Remark)
[YG occupancy: 387920 K (613440 K)]
65.550: [Rescan (parallel) , 0.0085125 secs]
65.559: [weak refs processing, 0.0000243 secs]
65.559: [class unloading, 0.0013120 secs]
65.560: [scrub symbol table, 0.0008345 secs]
65.561: [scrub string table, 0.0001759 secs]
[1 CMS-remark: 10812086K(11901376K)]
11200006K(12514816K), 0.0110730 secs]
[Times: user=0.06 sys=0.00, real=0.01 secs]
-05-26T16:23:08.458-0200: 65.561: [CMS-concurrent-sweep-start]
-05-26T16:23:08.485-0200: 65.588: [CMS-concurrent-sweep: 0.027/0.027 secs]
[Times: user=0.03 sys=0.00, real=0.03 secs]
-05-26T16:23:08.485-0200: 65.589: [CMS-concurrent-reset-start]
-05-26T16:23:08.497-0200: 65.601: [CMS-concurrent-reset: 0.012/0.012 secs]
[Times: user=0.01 sys=0.00, real=0.01 secs]
Minor GC(小型GC)
日志中的第一次GC事件是清理年轻代的小型GC(Minor GC)。让我们来分析 CMS 垃圾收集器的行为:
-05-26T16:23:07.219-0200: 64.322:[GC(Allocation Failure) 64.322:
[ParNew: 613404K->68068K``(613440K), 0.1020465 secs]
K->10880154K``(12514816K), 0.1021309 secs]
[Times: user=0.78 sys=0.01, real=0.11 secs]
1、
2015-05-26T16:23:07.219-0200 – GC事件开始的时间. 其中-0200表示西二时区,而中国所在的东8区为+0800。
2、64.322 – GC事件开始时,相对于JVM启动时的间隔时间,单位是秒。
3、GC– 用来区分Minor GC还是Full GC的标志。GC表明这是一次小型GC(Minor GC)
4、Allocation Failure– 触发垃圾收集的原因。本次GC事件, 是由于年轻代中没有适当的空间存放新的数据结构引起的。
5、ParNew– 垃圾收集器的名称。这个名字表示的是在年轻代中使用的: 并行的 标记-复制(mark-copy), 全线暂停(STW)垃圾收集器, 专门设计了用来配合老年代使用的Concurrent Mark & Sweep垃圾收集器。
6、613404K->68068K– 在垃圾收集之前和之后的年轻代使用量。
7、 (613440K) – 年轻代的总大小。
8、0.1020465 secs– 垃圾收集器在w/o final cleanup阶段消耗的时间
9、10885349K->10880154K– 在垃圾收集之前和之后堆内存的使用情况。
10. (12514816K) – 可用堆的总大小。
11.0.1021309 secs– 垃圾收集器在标记和复制年轻代存活对象时所消耗的时间。包括和ConcurrentMarkSweep收集器的通信开销, 提升存活时间达标的对象到老年代,以及垃圾收集后期的一些最终清理。
12. [Times: user=0.78 sys=0.01, real=0.11 secs] – GC事件的持续时间, 通过三个部分来衡量:
user – 在此次垃圾回收过程中, 由GC线程所消耗的总的CPU时间。
sys – GC过程中中操作系统调用和系统等待事件所消耗的时间。
real – 应用程序暂停的时间。在并行GC(Parallel GC)中, 这个数字约等于: (user time + system time)/GC线程数。 这里使用的是8个线程。 请注意,总是有固定比例的处理过程是不能并行化的。
从上面的日志可以看出,在GC之前总的堆内存使用量为 10,885,349K, 年轻代的使用量为 613,404K。
这意味着老年代使用量等于 10,271,945K。GC之后,年轻代的使用量减少了 545,336K, 而总的堆内存使用只下降了 5,195K。可以算出有 540,141K 的对象从年轻代提升到老年代。
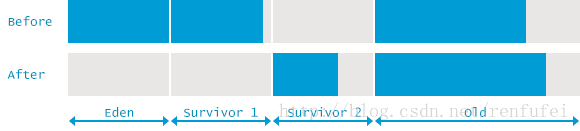
Full GC(完全GC)
现在, 我们已经熟悉了如何解读GC日志, 接下来将介绍一种完全不同的日志格式。下面这一段很长很长的日志, 就是CMS对老年代进行垃圾收集时输出的各阶段日志。为了简洁,我们对这些阶段逐个介绍。 首先来看CMS收集器整个GC事件的日志:
-05-26T16:23:07.321-0200: 64.425: [GC (CMS Initial Mark)
[1 CMS-initial-mark: 10812086K(11901376K)]
10887844K(12514816K), 0.0001997 secs]
[Times: user=0.00 sys=0.00, real=0.00 secs]
-05-26T16:23:07.321-0200: 64.425: [CMS-concurrent-mark-start]
-05-26T16:23:07.357-0200: 64.460: [CMS-concurrent-mark: 0.035/0.035 secs]
[Times: user=0.07 sys=0.00, real=0.03 secs]
-05-26T16:23:07.357-0200: 64.460: [CMS-concurrent-preclean-start]
-05-26T16:23:07.373-0200: 64.476: [CMS-concurrent-preclean: 0.016/0.016 secs]
[Times: user=0.02 sys=0.00, real=0.02 secs]
-05-26T16:23:07.373-0200: 64.476: [CMS-concurrent-abortable-preclean-start]
-05-26T16:23:08.446-0200: 65.550: [CMS-concurrent-abortable-preclean: 0.167/1.074 secs]
[Times: user=0.20 sys=0.00, real=1.07 secs]
-05-26T16:23:08.447-0200: 65.550: [GC (CMS Final Remark)
[YG occupancy: 387920 K (613440 K)]
65.550: [Rescan (parallel) , 0.0085125 secs]
65.559: [weak refs processing, 0.0000243 secs]
65.559: [class unloading, 0.0013120 secs]
65.560: [scrub symbol table, 0.0008345 secs]
65.561: [scrub string table, 0.0001759 secs]
[1 CMS-remark: 10812086K(11901376K)]
11200006K(12514816K), 0.0110730 secs]
[Times: user=0.06 sys=0.00, real=0.01 secs]
-05-26T16:23:08.458-0200: 65.561: [CMS-concurrent-sweep-start]
-05-26T16:23:08.485-0200: 65.588: [CMS-concurrent-sweep: 0.027/0.027 secs]
[Times: user=0.03 sys=0.00, real=0.03 secs]
-05-26T16:23:08.485-0200: 65.589: [CMS-concurrent-reset-start]
-05-26T16:23:08.497-0200: 65.601: [CMS-concurrent-reset: 0.012/0.012 secs]
[Times: user=0.01 sys=0.00, real=0.01 secs]
只是要记住 —— 在实际情况下, 进行老年代的并发回收时, 可能会伴随着多次年轻代的小型GC. 在这种情况下, 大型GC的日志中就会掺杂着多次小型GC事件, 像前面所介绍的一样。
阶段 1: Initial Mark(初始标记). 这是第一次STW事件。 此阶段的目标是标记老年代中所有存活的对象, 包括 GC ROOR 的直接引用, 以及由年轻代中存活对象所引用的对象。 后者也非常重要, 因为老年代是独立进行回收的。
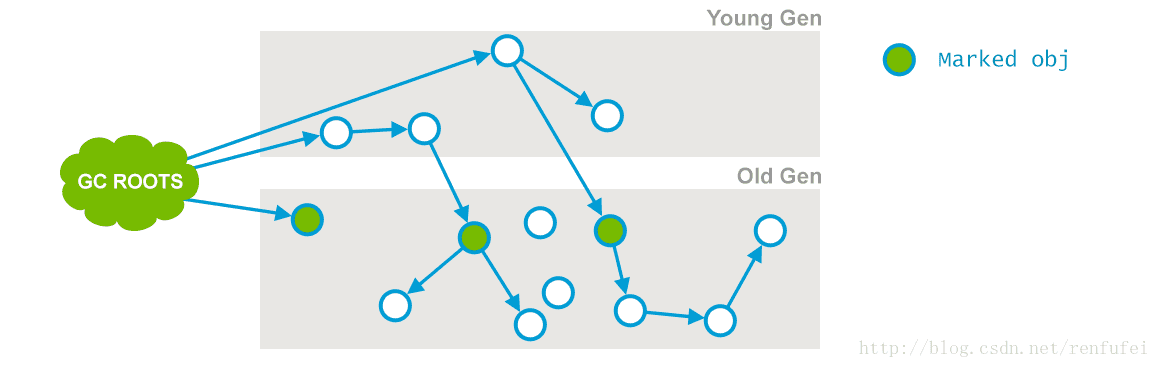
-05-26T16:23:07.321-0200: 64.421: [GC (CMS Initial Mark1
[1 CMS-initial-mark: 10812086K1(11901376K)1] 10887844K1(12514816K)1,
.0001997 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]1
、 2015-05-26T16:23:07.321-0200: 64.42 – GC事件开始的时间. 其中 -0200 是时区,而中国所在的东8区为 +0800。 而 64.42 是相对于JVM启动的时间。 下面的其他阶段也是一样,所以就不再重复介绍。
、 CMS Initial Mark – 垃圾回收的阶段名称为 “Initial Mark”。 标记所有的 GC Root。
、 10812086K – 老年代的当前使用量。
、 (11901376K) – 老年代中可用内存总量。
、 10887844K – 当前堆内存的使用量。
、 (12514816K) – 可用堆的总大小。
、 0.0001997 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] – 此次暂停的持续时间, 以 user, system 和 real time 3个部分进行衡量。
阶段 2: Concurrent Mark(并发标记). 在此阶段, 垃圾收集器遍历老年代, 标记所有的存活对象, 从前一阶段 “Initial Mark” 找到的 root 根开始算起。 顾名思义, “并发标记”阶段, 就是与应用程序同时运行,不用暂停的阶段。 请注意, 并非所有老年代中存活的对象都在此阶段被标记, 因为在标记过程中对象的引用关系还在发生变化。
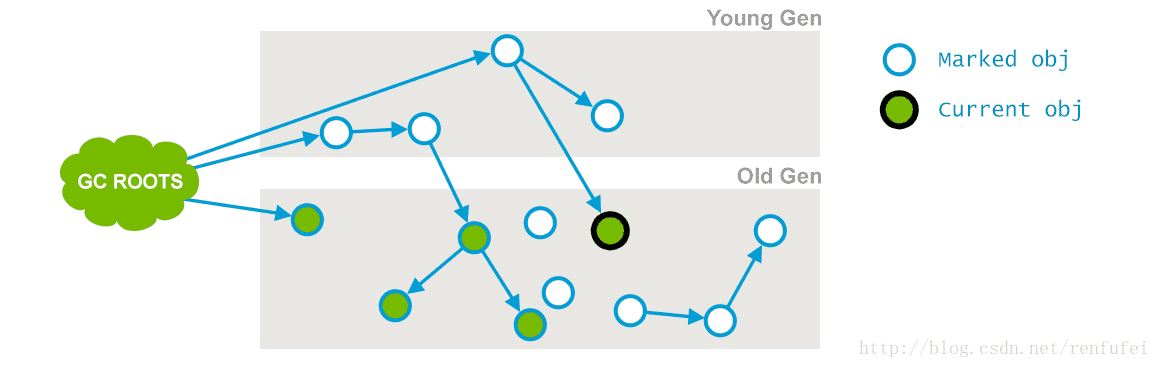
在上面的示意图中, “Current object” 旁边的一个引用被标记线程并发删除了。
-05-26T16:23:07.321-0200: 64.425: [CMS-concurrent-mark-start]
-05-26T16:23:07.357-0200: 64.460: [CMS-concurrent-mark1: 035/0.035 secs1]
[Times: user=0.07 sys=0.00, real=0.03 secs]1
、CMS-concurrent-mark – 并发标记(“Concurrent Mark”) 是CMS垃圾收集中的一个阶段, 遍历老年代并标记所有的存活对象。
、035/0.035 secs – 此阶段的持续时间, 分别是运行时间和相应的实际时间。
、[Times: user=0.07 sys=0.00, real=0.03 secs] – Times 这部分对并发阶段来说没多少意义, 因为是从并发标记开始时计算的,而这段时间内不仅并发标记在运行,程序也在运行
阶段 3: Concurrent Preclean(并发预清理). 此阶段同样是与应用线程并行执行的, 不需要停止应用线程。 因为前一阶段是与程序并发进行的,可能有一些引用已经改变。
如果在并发标记过程中发生了引用关系变化,JVM会(通过“Card”)将发生了改变的区域标记为“脏”区(这就是所谓的卡片标记,Card Marking)。
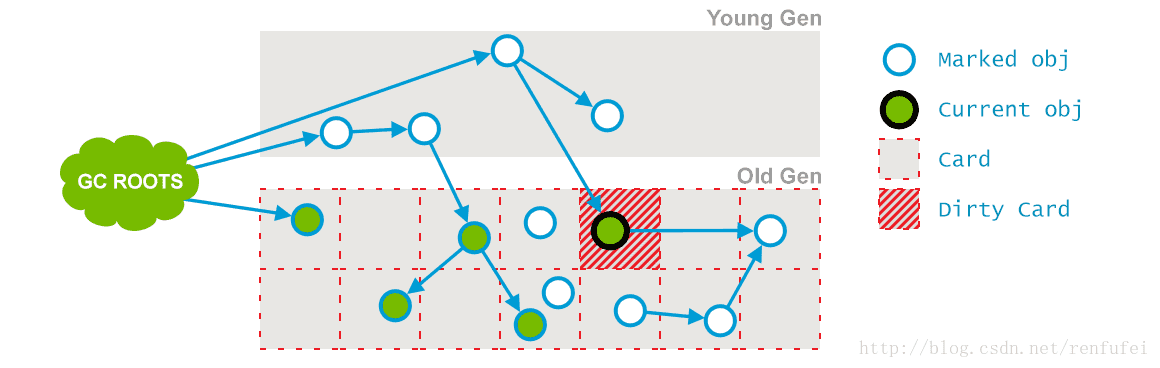
在预清理阶段,这些脏对象会被统计出来,从他们可达的对象也被标记下来。此阶段完成后, 用以标记的 card 也就被清空了。
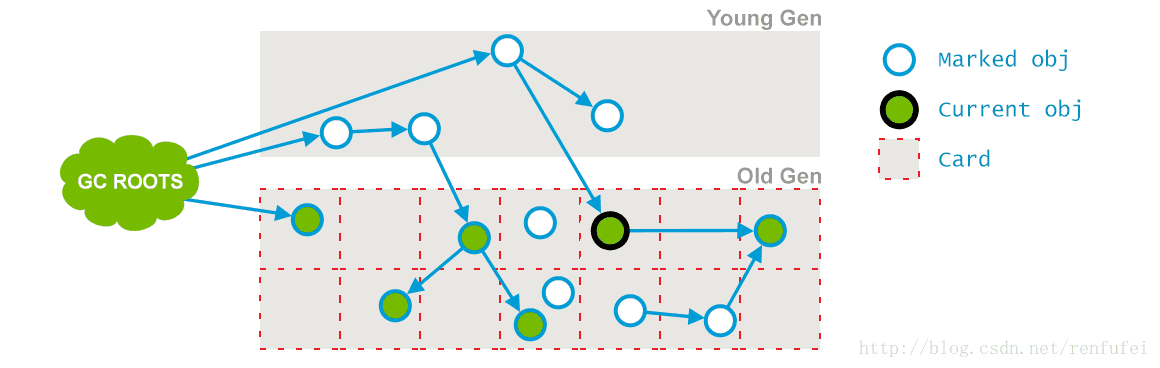
此外, 本阶段也会执行一些必要的细节处理, 并为Final Remark 阶段做一些准备工作。
-05-26T16:23:07.357-0200: 64.460: [CMS-concurrent-preclean-start]
-05-26T16:23:07.373-0200: 64.476: [CMS-concurrent-preclean: 0.016/0.016 secs] [Times: user=0.02 sys=0.00, real=0.02 secs]
、CMS-concurrent-preclean – 并发预清理阶段, 统计此前的标记阶段中发生了改变的对象。
、0.016/0.016 secs – 此阶段的持续时间, 分别是运行时间和对应的实际时间。
、[Times: user=0.02 sys=0.00, real=0.02 secs] – Times 这部分对并发阶段来说没多少意义,
因为是从并发标记开始时计算的,而这段时间内不仅GC的并发标记在运行,程序也在运行。
阶段 4: Concurrent Abortable Preclean(并发可取消的预清理). 此阶段也不停止应用线程. 本阶段尝试在 STW 的 Final Remark 之前尽可能地多做一些工作。本阶段的具体时间取决于多种因素, 因为它循环做同样的事情,直到满足某个退出条件( 如迭代次数, 有用工作量, 消耗的系统时间,等等)。
-05-26T16:23:07.373-0200: 64.476: [CMS-concurrent-abortable-preclean-start]
-05-26T16:23:08.446-0200: 65.550: [CMS-concurrent-abortable-preclean1: 0.167/1.074 secs2][Times: user=0.20 sys=0.00, real=1.07 secs]3
、 CMS-concurrent-abortable-preclean – 此阶段的名称: “Concurrent Abortable Preclean”。
、 0.167/1.074 secs – 此阶段的持续时间, 运行时间和对应的实际时间。有趣的是, 用户时间明显比时钟时间要小很多。通常情况下我们看到的都是时钟时间小于用户时间, 这意味着因为有一些并行工作, 所以运行时间才会小于使用的CPU时间。这里只进行了少量的工作 — 0.167秒的CPU时间,GC线程经历了很多系统等待。从本质上讲,GC线程试图在必须执行 STW暂停之前等待尽可能长的时间。默认条件下,此阶段可以持续最多5秒钟。
、 [Times: user=0.20 sys=0.00, real=1.07 secs] – “Times” 这部分对并发阶段来说没多少意义, 因为是从并发标记开始时计算的,而这段时间内不仅GC的并发标记线程在运行,程序也在运行
此阶段可能显著影响STW停顿的持续时间, 并且有许多重要的配置选项和失败模式。
阶段 5: Final Remark(最终标记).这是此次GC事件中第二次(也是最后一次)STW阶段。本阶段的目标是完成老年代中所有存活对象的标记. 因为之前的 preclean 阶段是并发的, 有可能无法跟上应用程序的变化速度。所以需要 STW暂停来处理复杂情况。
通常CMS会尝试在年轻代尽可能空的情况运行 final remark 阶段, 以免接连多次发生 STW 事件。
看起来稍微比之前的阶段要复杂一些:
-05-26T16:23:08.447-0200: 65.550: [GC (CMS Final Remark) [YG occupancy: 387920 K (613440 K)]
.550: [Rescan (parallel) , 0.0085125 secs] 65.559: [weak refs processing, 0.0000243 secs]65.559: [class unloading, 0.0013120 secs]65.560: [scrub string table, 0.0001759 secs]
[1 CMS-remark: 10812086K(11901376K)] 11200006K(12514816K),0.0110730 secs] [Times: user=0.06 sys=0.00, real=0.01 secs]
、 2015-05-26T16:23:08.447-0200: 65.550 – GC事件开始的时间. 包括时钟时间,以及相对于JVM启动的时间. 其中-0200表示西二时区,而中国所在的东8区为 +0800。
、 CMS Final Remark – 此阶段的名称为 “Final Remark”, 标记老年代中所有存活的对象,包括在此前的并发标记过程中创建/修改的引用。
、 YG occupancy: 387920 K (613440 K) – 当前年轻代的使用量和总容量。
、 [Rescan (parallel) , 0.0085125 secs] – 在程序暂停时重新进行扫描(Rescan),以完成存活对象的标记。此时 rescan 是并行执行的,消耗的时间为 0.0085125秒。
、 weak refs processing, 0.0000243 secs]65.559 – 处理弱引用的第一个子阶段(sub-phases)。 显示的是持续时间和开始时间戳。
、 class unloading, 0.0013120 secs]65.560 – 第二个子阶段, 卸载不使用的类。 显示的是持续时间和开始的时间戳。
、 scrub string table, 0.0001759 secs – 最后一个子阶段, 清理持有class级别 metadata 的符号表(symbol tables),以及内部化字符串对应的 string tables。当然也显示了暂停的时钟时间。
、 10812086K(11901376K) – 此阶段完成后老年代的使用量和总容量
、 11200006K(12514816K) – 此阶段完成后整个堆内存的使用量和总容量
. 0.0110730 secs – 此阶段的持续时间。
. [Times: user=0.06 sys=0.00, real=0.01 secs] – GC事件的持续时间, 通过不同的类别来衡量: user, system and real time。
在5个标记阶段完成之后, 老年代中所有的存活对象都被标记了, 现在GC将清除所有不使用的对象来回收老年代空间:
阶段 6:Concurrent Sweep(并发清除). 此阶段与应用程序并发执行,不需要STW停顿。目的是删除未使用的对象,并收回他们占用的空间。
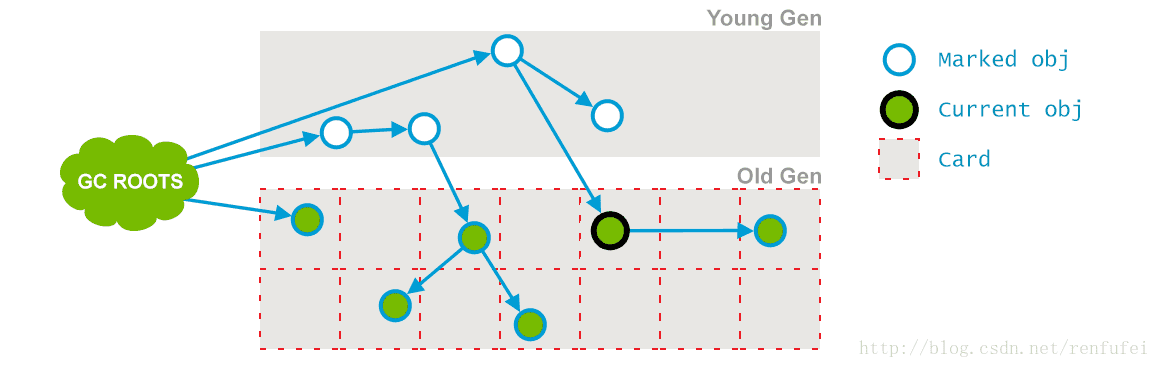
-05-26T16:23:08.458-0200: 65.561: [CMS-concurrent-sweep-start] 2015-05-26T16:23:08.485-0200: 65.588: [CMS-concurrent-sweep: 0.027/0.027 secs] [Times: user=0.03 sys=0.00, real=0.03 secs]
、 CMS-concurrent-sweep – 此阶段的名称, “Concurrent Sweep”, 清除未被标记、不再使用的对象以释放内存空间。
、 0.027/0.027 secs – 此阶段的持续时间, 分别是运行时间和实际时间
、 [Times: user=0.03 sys=0.00, real=0.03 secs] – “Times”部分对并发阶段来说没有多少意义, 因为是从并发标记开始时计算的,而这段时间内不仅是并发标记在运行,程序也在运行。
阶段 7:Concurrent Reset(并发重置). 此阶段与应用程序并发执行,重置CMS算法相关的内部数据, 为下一次GC循环做准备。
-05-26T16:23:08.485-0200: 65.589: [CMS-concurrent-reset-start] 2015-05-26T16:23:08.497-0200: 65.601: [CMS-concurrent-reset: 0.012/0.012 secs] [Times: user=0.01 sys=0.00, real=0.01 secs]
、 CMS-concurrent-reset – 此阶段的名称, “Concurrent Reset”, 重置CMS算法的内部数据结构, 为下一次GC循环做准备。
、 0.012/0.012 secs – 此阶段的持续时间, 分别是运行时间和对应的实际时间
、 [Times: user=0.01 sys=0.00, real=0.01 secs] – “Times”部分对并发阶段来说没多少意义, 因为是从并发标记开始时计算的,而这段时间内不仅GC线程在运行,程序也在运行。
总之, CMS垃圾收集器在减少停顿时间上做了很多给力的工作,大量的并发线程执行的工作并不需要暂停应用线程。 当然, CMS也有一些缺点,其中最大的问题就是老年代内存碎片问题, 在某些情况下GC会造成不可预测的暂停时间, 特别是堆内存较大的情况下。
G1 – Garbage First(垃圾优先算法)
G1最主要的设计目标是: 将STW停顿的时间和分布变成可预期以及可配置的。事实上,G1是一款软实时垃圾收集器, 也就是说可以为其设置某项特定的性能指标.
可以指定: 在任意 xx 毫秒的时间范围内,STW停顿不得超过 x 毫秒。
如: 任意1秒暂停时间不得超过5毫秒. Garbage-First GC 会尽力达成这个目标(有很大的概率会满足, 但并不完全确定,具体是多少将是硬实时的[hard real-time])。
为了达成这项指标, G1 有一些独特的实现。首先,堆不再分成连续的年轻代和老年代空间。
而是划分为多个(通常是2048个)可以存放对象的 小堆区(smaller heap regions)。每个小堆区都可能是 Eden区, Survivor区或者Old区. 在逻辑上, 所有的Eden区和Survivor区合起来就是年轻代, 所有的Old区拼在一起那就是老年代:
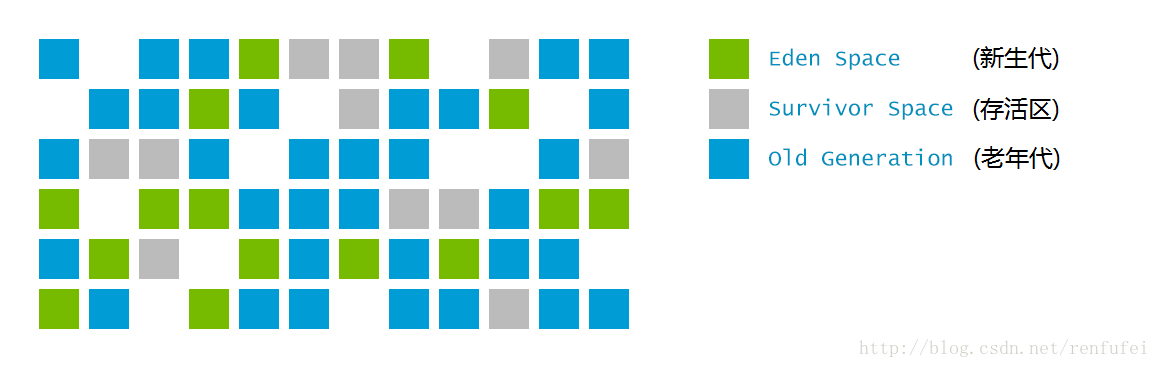
这样的划分使得 GC不必每次都去收集整个堆空间, 而是以增量的方式来处理: 每次只处理一部分小堆区,称为此次的回收集(collection set). 每次暂停都会收集所有年轻代的小堆区, 但可能只包含一部分老年代小堆区:
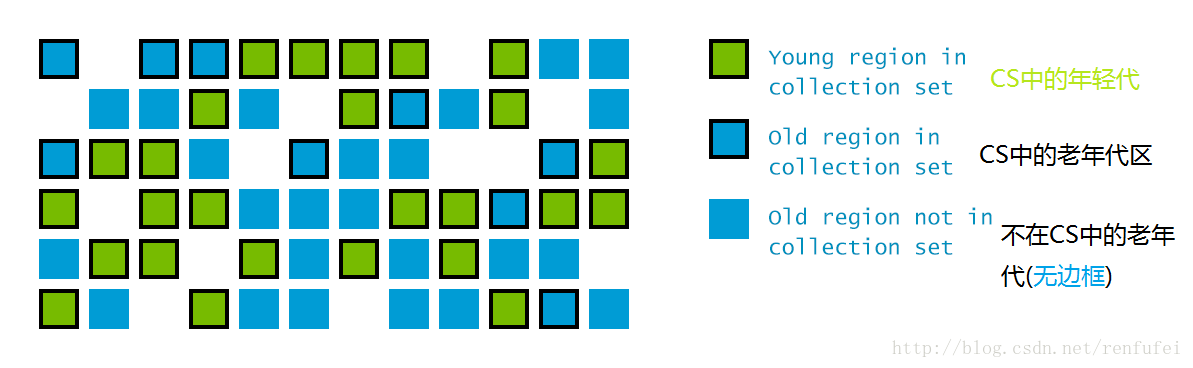
G1的另一项创新, 是在并发阶段估算每个小堆区存活对象的总数。用来构建回收集(collection set)的原则是: 垃圾最多的小堆区会被优先收集。这也是G1名称的由来: garbage-first。
要启用G1收集器, 使用的命令行参数为:
java -XX:+UseG1GC com.mypackages.MyExecutableClass
Evacuation Pause: Fully Young(转移暂停:纯年轻代模式)
在应用程序刚启动时, G1还未执行过(not-yet-executed)并发阶段, 也就没有获得任何额外的信息, 处于初始的 fully-young 模式.
在年轻代空间用满之后, 应用线程被暂停, 年轻代堆区中的存活对象被复制到存活区, 如果还没有存活区,则选择任意一部分空闲的小堆区用作存活区。
复制的过程称为转移(Evacuation),这和前面讲过的年轻代收集器基本上是一样的工作原理。转移暂停的日志信息很长,为简单起见, 我们去除了一些不重要的信息. 在并发阶段之后我们会进行详细的讲解。
此外, 由于日志记录很多, 所以并行阶段和“其他”阶段的日志将拆分为多个部分来进行讲解:
.134: [GC pause (G1 Evacuation Pause) (young), 0.0144119 secs]
[Parallel Time: 13.9 ms, GC Workers: 8]
…
[Code Root Fixup: 0.0 ms]
[Code Root Purge: 0.0 ms]
[Clear CT: 0.1 ms]
[Other: 0.4 ms]
…
[Eden: 24.0M(24.0M)->0.0B(13.0M) Survivors: 0.0B->3072.0K Heap: 24.0M(256.0M)->21.9M(256.0M)]
[Times: user=0.04 sys=0.04, real=0.02 secs]
、 0.134: [GC pause (G1 Evacuation Pause) (young), 0.0144119 secs] – G1转移暂停,只清理年轻代空间。暂停在JVM启动之后 134 ms 开始, 持续的系统时间为 0.0144秒 。
、 [Parallel Time: 13.9 ms, GC Workers: 8] – 表明后面的活动由8个 Worker 线程并行执行, 消耗时间为13.9毫秒(real time)。
、 … – 为阅读方便, 省略了部分内容,请参考后文。
、 [Code Root Fixup: 0.0 ms] – 释放用于管理并行活动的内部数据。一般都接近于零。这是串行执行的过程。
、 [Code Root Purge: 0.0 ms] – 清理其他部分数据, 也是非常快的, 但如非必要则几乎等于零。这是串行执行的过程。
、 [Other: 0.4 ms] – 其他活动消耗的时间, 其中有很多是并行执行的。
、 … – 请参考后文。
、 [Eden: 24.0M(24.0M)->0.0B(13.0M) – 暂停之前和暂停之后, Eden 区的使用量/总容量。
、 Survivors: 0.0B->3072.0K – 暂停之前和暂停之后, 存活区的使用量。
. Heap: 24.0M(256.0M)->21.9M(256.0M)] – 暂停之前和暂停之后, 整个堆内存的使用量与总容量。
. [Times: user=0.04 sys=0.04, real=0.02 secs] – GC事件的持续时间, 通过三个部分来衡量:
user– 在此次垃圾回收过程中, 由GC线程所消耗的总的CPU时间。sys– GC过程中, 系统调用和系统等待事件所消耗的时间。real– 应用程序暂停的时间。在并行GC(Parallel GC)中, 这个数字约等于: (user time + system time)/GC线程数。 这里使用的是8个线程。 请注意,总是有一定比例的处理过程是不能并行化的。
说明: 系统时间(wall clock time, elapsed time), 是指一段程序从运行到终止,系统时钟走过的时间。一般来说,系统时间都是要大于CPU时间
最繁重的GC任务由多个专用的 worker 线程来执行。下面的日志描述了他们的行为:
[Parallel Time: 13.9 ms, GC Workers: 8]
[GC Worker Start (ms): Min: 134.0, Avg: 134.1, Max: 134.1, Diff: 0.1]
[Ext Root Scanning (ms): Min: 0.1, Avg: 0.2, Max: 0.3, Diff: 0.2, Sum: 1.2]
[Update RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Processed Buffers: Min: 0, Avg: 0.0, Max: 0, Diff: 0, Sum: 0]
[Scan RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Code Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.2, Diff: 0.2, Sum: 0.2]
[Object Copy (ms): Min: 10.8, Avg: 12.1, Max: 12.6, Diff: 1.9, Sum: 96.5]
[Termination (ms): Min: 0.8, Avg: 1.5, Max: 2.8, Diff: 1.9, Sum: 12.2]
[Termination Attempts: Min: 173, Avg: 293.2, Max: 362, Diff: 189, Sum: 2346]
[GC Worker Other (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1]
GC Worker Total (ms): Min: 13.7, Avg: 13.8, Max: 13.8, Diff: 0.1, Sum: 110.2]
[GC Worker End (ms): Min: 147.8, Avg: 147.8, Max: 147.8, Diff: 0.0]
、[Parallel Time: 13.9 ms, GC Workers: 8] – 表明下列活动由8个线程并行执行,消耗的时间为13.9毫秒(real time)。
、[GC Worker Start (ms) – GC的worker线程开始启动时,相对于 pause 开始的时间戳。如果 Min 和 Max 差别很大,则表明本机其他进程所使用的线程数量过多, 挤占了GC的CPU时间。
、[Ext Root Scanning (ms) – 用了多长时间来扫描堆外(non-heap)的root, 如 classloaders, JNI引用, JVM的系统root等。后面显示了运行时间, “Sum” 指的是CPU时间。
、[Code Root Scanning (ms) – 用了多长时间来扫描实际代码中的 root: 例如局部变量等等(local vars)。
、[Object Copy (ms) – 用了多长时间来拷贝收集区内的存活对象。
、[Termination (ms) – GC的worker线程用了多长时间来确保自身可以安全地停止, 这段时间什么也不用做, stop 之后该线程就终止运行了。
、[Termination Attempts – GC的worker 线程尝试多少次 try 和 teminate。如果worker发现还有一些任务没处理完,则这一次尝试就是失败的, 暂时还不能终止。
、[GC Worker Other (ms) – 一些琐碎的小活动,在GC日志中不值得单独列出来。
、GC Worker Total (ms) – GC的worker 线程的工作时间总计。
、[GC Worker End (ms) – GC的worker 线程完成作业的时间戳。通常来说这部分数字应该大致相等, 否则就说明有太多的线程被挂起, 很可能是因为[坏邻居效应(noisy neighbor)](https://github.com/cncounter/translation/blob/master/tiemao_2016/45_noisy_neighbors/noisy_neighbor_cloud%20_performance.md) 所导致的。
此外,在转移暂停期间,还有一些琐碎执行的小活动。这里我们只介绍其中的一部分, 其余的会在后面进行讨论。
[Other: 0.4 ms]
[Choose CSet: 0.0 ms]
[Ref Proc: 0.2 ms]
[Ref Enq: 0.0 ms]
[Redirty Cards: 0.1 ms]
[Humongous Register: 0.0 ms]
[Humongous Reclaim: 0.0 ms]
[Free CSet: 0.0 ms]
、 [Other: 0.4 ms] – 其他活动消耗的时间, 其中有很多也是并行执行的。
、 [Ref Proc: 0.2 ms] – 处理非强引用(non-strong)的时间: 进行清理或者决定是否需要清理。
、 [Ref Enq: 0.0 ms] – 用来将剩下的 non-strong 引用排列到合适的 ReferenceQueue中。
、 [Free CSet: 0.0 ms] – 将回收集中被释放的小堆归还所消耗的时间, 以便他们能用来分配新的对象。
Concurrent Marking(并发标记)
G1收集器的很多概念建立在CMS的基础上,所以下面的内容需要你对CMS有一定的理解. 虽然也有很多地方不同, 但并发标记的目标基本上是一样的. G1的并发标记通过 Snapshot-At-The-Beginning(开始时快照) 的方式, 在标记阶段开始时记下所有的存活对象。
即使在标记的同时又有一些变成了垃圾. 通过对象是存活信息, 可以构建出每个小堆区的存活状态, 以便回收集能高效地进行选择。
这些信息在接下来的阶段会用来执行老年代区域的垃圾收集。在两种情况下是完全地并发执行的: – – – – -一、如果在标记阶段确定某个小堆区只包含垃圾;
-二、在STW转移暂停期间, 同时包含垃圾和存活对象的老年代小堆区。
当堆内存的总体使用比例达到一定数值时,就会触发并发标记。默认值为 45%, 但也可以通过JVM参数 InitiatingHeapOccupancyPercent 来设置。
和CMS一样, G1的并发标记也是由多个阶段组成, 其中一些是完全并发的, 还有一些阶段需要暂停应用线程。
阶段 1: Initial Mark(初始标记)。 此阶段标记所有从GC root 直接可达的对象。在CMS中需要一次STW暂停, 但G1里面通常是在转移暂停的同时处理这些事情, 所以它的开销是很小的. 可以在 Evacuation Pause 日志中的第一行看到(initial-mark)暂停:
.631: [GC pause (G1 Evacuation Pause) (young) (initial-mark), 0.0062656 secs]
阶段 2: Root Region Scan(Root区扫描). 此阶段标记所有从 “根区域” 可达的存活对象。 根区域包括: 非空的区域, 以及在标记过程中不得不收集的区域。
因为在并发标记的过程中迁移对象会造成很多麻烦, 所以此阶段必须在下一次转移暂停之前完成。
如果必须启动转移暂停, 则会先要求根区域扫描中止, 等它完成才能继续扫描. 在当前版本的实现中, 根区域是存活的小堆区: y包括下一次转移暂停中肯定会被清理的那部分年轻代小堆区。
.362: [GC concurrent-root-region-scan-start]
.364: [GC concurrent-root-region-scan-end, 0.0028513 secs]
阶段 3:Concurrent Mark(并发标记). 此阶段非常类似于CMS: 它只是遍历对象图, 并在一个特殊的位图中标记能访问到的对象. 为了确保标记开始时的快照准确性, 所有应用线程并发对对象图执行的引用更新,G1 要求放弃前面阶段为了标记目的而引用的过时引用。
这是通过使用 Pre-Write 屏障来实现的,(不要和之后介绍的 Post-Write 混淆, 也不要和多线程开发中的内存屏障(memory barriers)相混淆)。Pre-Write屏障的作用是: G1在进行并发标记时, 如果程序将对象的某个属性做了变更, 就会在 log buffers 中存储之前的引用。 由并发标记线程负责处理。
.364: [GC concurrent-mark-start]
.645: [GC co ncurrent-mark-end, 0.2803470 secs]
阶段 4: Remark(再次标记).和CMS类似,这也是一次STW停顿,以完成标记过程。对于G1,它短暂地停止应用线程, 停止并发更新日志的写入, 处理其中的少量信息,并标记所有在并发标记开始时未被标记的存活对象。这一阶段也执行某些额外的清理, 如引用处理(参见 Evacuation Pause log) 或者类卸载(class unloading)。
.645: [GC remark 1.645: [Finalize Marking, 0.0009461 secs]
.646: [GC ref-proc, 0.0000417 secs] 1.646:
[Unloading, 0.0011301 secs], 0.0074056 secs]
[Times: user=0.01 sys=0.00, real=0.01 secs]
阶段 5: Cleanup(清理). 最后这个小阶段为即将到来的转移阶段做准备, 统计小堆区中所有存活的对象, 并将小堆区进行排序, 以提升GC的效率. 此阶段也为下一次标记执行所有必需的整理工作(house-keeping activities): 维护并发标记的内部状态。
最后要提醒的是, 所有不包含存活对象的小堆区在此阶段都被回收了。有一部分是并发的: 例如空堆区的回收,还有大部分的存活率计算, 此阶段也需要一个短暂的STW暂停, 以不受应用线程的影响来完成作业. 这种STW停顿的日志如下:
.652: [GC cleanup 1213M->1213M(1885M), 0.0030492 secs]
[Times: user=0.01 sys=0.00, real=0.00 secs]
如果发现某些小堆区中只包含垃圾, 则日志格式可能会有点不同, 如:
、872: [GC cleanup 1357M->173M(1996M), 0.0015664 secs]
[Times: user=0.01 sys=0.00, real=0.01 secs]
、874: [GC concurrent-cleanup-start]
、876: [GC concurrent-cleanup-end, 0.0014846 secs]
Evacuation Pause: Mixed (转移暂停: 混合模式)
能并发清理老年代中整个整个的小堆区是一种最优情形, 但有时候并不是这样。并发标记完成之后, G1将执行一次混合收集(mixed collection), 不只清理年轻代, 还将一部分老年代区域也加入到 collection set 中。
混合模式的转移暂停(Evacuation pause)不一定紧跟着并发标记阶段。有很多规则和历史数据会影响混合模式的启动时机。比如, 假若在老年代中可以并发地腾出很多的小堆区,就没有必要启动混合模式。
因此, 在并发标记与混合转移暂停之间, 很可能会存在多次 fully-young 转移暂停。
添加到回收集的老年代小堆区的具体数字及其顺序, 也是基于许多规则来判定的。
其中包括指定的软实时性能指标, 存活性,以及在并发标记期间收集的GC效率等数据, 外加一些可配置的JVM选项. 混合收集的过程, 很大程度上和前面的 fully-young gc 是一样的, 但这里我们还要介绍一个概念: remembered sets(历史记忆集)。
Remembered sets (历史记忆集)是用来支持不同的小堆区进行独立回收的。例如,在收集A、B、C区时, 我们必须要知道是否有从D区或者E区指向其中的引用, 以确定他们的存活性.
但是遍历整个堆需要相当长的时间, 这就违背了增量收集的初衷, 因此必须采取某种优化手段. 其他GC算法有独立的 Card Table 来支持年轻代的垃圾收集一样, 而G1中使用的是 Remembered Sets。
如下图所示, 每个小堆区都有一个 remembered set, 列出了从外部指向本区的所有引用。这些引用将被视为附加的 GC root. 注意,在并发标记过程中,老年代中被确定为垃圾的对象会被忽略, 即使有外部引用指向他们: 因为在这种情况下引用者也是垃圾。
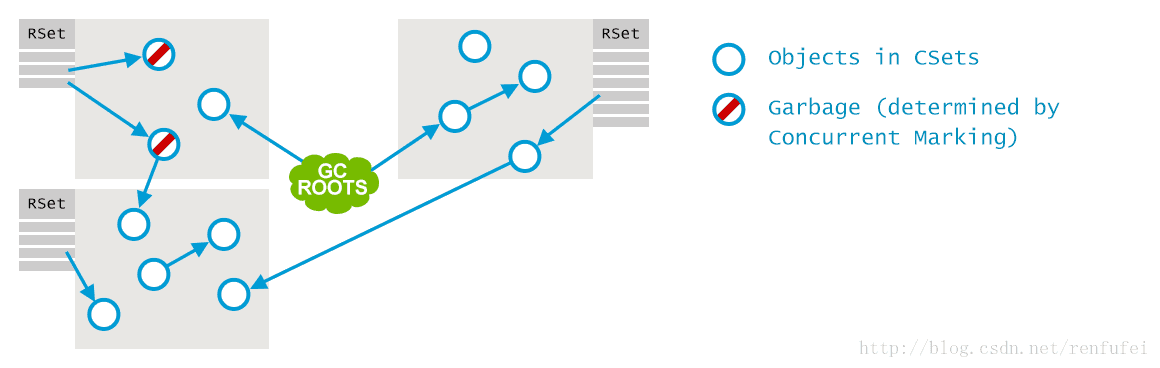
接下来的行为,和其他垃圾收集器一样: 多个GC线程并行地找出哪些是存活对象,确定哪些是垃圾:

最后, 存活对象被转移到存活区(survivor regions), 在必要时会创建新的小堆区。现在,空的小堆区被释放, 可用于存放新的对象了。

为了维护 remembered set, 在程序运行的过程中, 只要写入某个字段,就会产生一个 Post-Write 屏障。如果生成的引用是跨区域的(cross-region),即从一个区指向另一个区, 就会在目标区的Remembered Set中,出现一个对应的条目。
为了减少 Write Barrier 造成的开销, 将卡片放入Remembered Set 的过程是异步的, 而且经过了很多的优化. 总体上是这样: Write Barrier 把脏卡信息存放到本地缓冲区(local buffer), 有专门的GC线程负责收集, 并将相关信息传给被引用区的 remembered set。
混合模式下的日志, 和纯年轻代模式相比, 可以发现一些有趣的地方:
[[Update RS (ms): Min: 0.7, Avg: 0.8, Max: 0.9, Diff: 0.2, Sum: 6.1]
[Processed Buffers: Min: 0, Avg: 2.2, Max: 5, Diff: 5, Sum: 18]
[Scan RS (ms): Min: 0.0, Avg: 0.1, Max: 0.2, Diff: 0.2, Sum: 0.8]
[Clear CT: 0.2 ms]
[Redirty Cards: 0.1 ms]
、 [Update RS (ms) – 因为 Remembered Sets 是并发处理的,必须确保在实际的垃圾收集之前, 缓冲区中的 card 得到处理。如果card数量很多, 则GC并发线程的负载可能就会很高。可能的原因是, 修改的字段过多, 或者CPU资源受限。
、 [Processed Buffers – 每个 worker 线程处理了多少个本地缓冲区(local buffer)。
、 [Scan RS (ms) – 用了多长时间扫描来自RSet的引用。
、 [Clear CT: 0.2 ms] – 清理 card table 中 cards 的时间。清理工作只是简单地删除“脏”状态, 此状态用来标识一个字段是否被更新的, 供Remembered Sets使用。
、 [Redirty Cards: 0.1 ms] – 将 card table 中适当的位置标记为 dirty 所花费的时间。”适当的位置”是由GC本身执行的堆内存改变所决定的, 例如引用排队等。
总结
通过本节内容的学习, 你应该对G1垃圾收集器有了一定了解。当然, 为了简洁, 我们省略了很多实现细节, 例如如何处理巨无霸对象(humongous objects)。
综合来看, G1是HotSpot中最先进的准产品级(production-ready)垃圾收集器。重要的是, HotSpot 工程师的主要精力都放在不断改进G1上面, 在新的java版本中,将会带来新的功能和优化。
可以看到, G1 解决了 CMS 中的各种疑难问题, 包括暂停时间的可预测性, 并终结了堆内存的碎片化。
对单业务延迟非常敏感的系统来说, 如果CPU资源不受限制,那么G1可以说是 HotSpot 中最好的选择, 特别是在最新版本的Java虚拟机中。
当然,这种降低延迟的优化也不是没有代价的: 由于额外的写屏障(write barriers)和更积极的守护线程, G1的开销会更大。
所以, 如果系统属于吞吐量优先型的, 又或者CPU持续占用100%, 而又不在乎单次GC的暂停时间, 那么CMS是更好的选择。
总之: G1适合大内存,需要低延迟的场景。
选择正确的GC算法,唯一可行的方式就是去尝试,并找出不对劲的地方, 在下一章我们将给出一般指导原则。
注意,G1可能会成为Java 9的默认GC: http://openjdk.java.net/jeps/248
Shenandoah 的性能
译注: Shenandoah: 谢南多厄河; 情人渡,水手谣; –> 此款GC暂时没有标准的中文译名; 翻译为大水手垃圾收集器?
我们列出了HotSpot中可用的所有 “准生产级” 算法。还有一种还在实验室中的算法, 称为超低延迟垃圾收集器(Ultra-Low-Pause-Time Garbage Collector).
它的设计目标是管理大型的多核服务器上,超大型的堆内存: 管理 100GB 及以上的堆容量, GC暂停时间小于 10ms。 当然,也是需要和吞吐量进行权衡的: 没有GC暂停的时候,算法的实现对吞吐量的性能损失不能超过10%
在新算法作为准产品级进行发布之前,我们不准备去讨论具体的实现细节,但它也构建在前面所提到的很多算法的基础上, 例如并发标记和增量收集。
但其中有很多东西是不同的。它不再将堆内存划分成多个代, 而是只采用单个空间. 没错, Shenandoah 并不是一款分代垃圾收集器。
这也就不再需要 card tables 和 remembered sets. 它还使用转发指针(forwarding pointers), 以及Brooks 风格的读屏障(Brooks style read barrier), 以允许对存活对象的并发复制, 从而减少GC暂停的次数和时间。
写完了如果写得有什么问题,希望读者能够给小编留言,也可以点击[此处扫下面二维码关注微信公众号](https://www.ycbbs.vip/?p=28 "此处扫下面二维码关注微信公众号")
看完两件小事
如果你觉得这篇文章对你挺有启发,我想请你帮我两个小忙:
- 把这篇文章分享给你的朋友 / 交流群,让更多的人看到,一起进步,一起成长!
- 关注公众号 「方志朋」,公众号后台回复「666」 免费领取我精心整理的进阶资源教程

本文著作权归作者所有,如若转载,请注明出处
转载请注明:文章转载自「 Java极客技术学习 」https://www.javajike.com
 微信扫一扫
微信扫一扫