
leetCode-10-Regular-Expression-Matching
题目描述(困难难度)

一个简单规则的匹配,「点.」代表任意字符,「星号*」 代表前一个字符重复 0 次或任意次。
解法一 递归
假如没有通配符 * ,这道题的难度就会少了很多,我们只需要一个字符,一个字符匹配就行。如果对递归不是很了解,强烈建议看下这篇文章,可以理清一下递归的思路。
- 我们假设存在这么个函数 isMatch,它将告诉我们 text 和 pattern 是否匹配
boolean isMatch ( String text, String pattern ) ;
-
递归规模减小
text 和 pattern 匹配,等价于 text 和 patten 的第一个字符匹配并且剩下的字符也匹配,而判断剩下的字符是否匹配,我们就可以调用 isMatch 函数。也就是
(pattern.charAt(0) == text.charAt(0) || pattern.charAt(0) == '.')&&isMatch(text.substring(1), pattern.substring(1)); - 递归出口
随着规模的减小, 当 pattern 为空时,如果 text 也为空,就返回 True,不然的话就返回 False 。
if (pattern.isEmpty()) return text.isEmpty();
综上,我们的代码是
public boolean isMatch(String text, String pattern) {
if (pattern.isEmpty()) return text.isEmpty();
//判断 text 是否为空,防止越界,如果 text 为空, 表达式直接判为 false, text.charAt(0)就不会执行了
boolean first_match = (!text.isEmpty() &&
(pattern.charAt(0) == text.charAt(0) || pattern.charAt(0) == '.'));
return first_match && isMatch(text.substring(1), pattern.substring(1));
}
当我们考虑了 * 呢,对于递归规模的减小,会增加对于 * 的判断,直接看代码吧。
public boolean isMatch(String text, String pattern) {
if (pattern.isEmpty()) return text.isEmpty();
boolean first_match = (!text.isEmpty() &&
(pattern.charAt(0) == text.charAt(0) || pattern.charAt(0) == '.'));
//只有长度大于 2 的时候,才考虑 *
if (pattern.length() >= 2 && pattern.charAt(1) == '*'){
//两种情况
//pattern 直接跳过两个字符。表示 * 前边的字符出现 0 次
//pattern 不变,例如 text = aa ,pattern = a*,第一个 a 匹配,然后 text 的第二个 a 接着和 pattern 的第一个 a 进行匹配。表示 * 用前一个字符替代。
return (isMatch(text, pattern.substring(2)) ||
(first_match && isMatch(text.substring(1), pattern)));
} else {
return first_match && isMatch(text.substring(1), pattern.substring(1));
}
}
时间复杂度:有点儿小复杂,待更。
空间复杂度:有点儿小复杂,待更。
解法二 动态规划
上边的递归,为了方便理解,简化下思路。
为了判断 text [ 0,len ] 的情况,需要知道 text [ 1,len ]
为了判断 text [ 1,len ] 的情况,需要知道 text [ 2,len ]
为了判断 text [ 2,len ] 的情况,需要知道 text [ 3,len ]
…
为了判断 text [ len – 1,len ] 的情况,需要知道 text [ len,len ]
text [ len,len ] 肯定好求
求出 text [ len,len ] 的情况,就知道了 text [ len – 1,len ]
求出 text [ len – 1,len ] 的情况,就知道了 text [ len – 2,len ]
…
求出 text [ 2,len ] 的情况,就知道了 text [1,len ]
求出 text [ l1,len ] 的情况,就知道了 text [ 0,len ]
从而知道了 text [ 0,len ] 的情况,求得问题的解。
上边就是先压栈,然后出栈,其实我们可以直接倒过来求,可以省略压栈的过程。
我们先求 text [ len,len ] 的情况
利用 text [ len,len ] 的情况 ,再求 text [ len – 1,len ] 的情况
…
利用 text [ 2,len ] 的情况 ,再求 text [ 1,len ] 的情况
利用 text [1,len ] 的情况 ,再求 text [ 0,len ] 的情况
从而求出问题的解
我们用 dp[i][j]表示 text 从 i 开始到最后,pattern 从 j 开始到最后,此时 text 和 pattern 是否匹配。
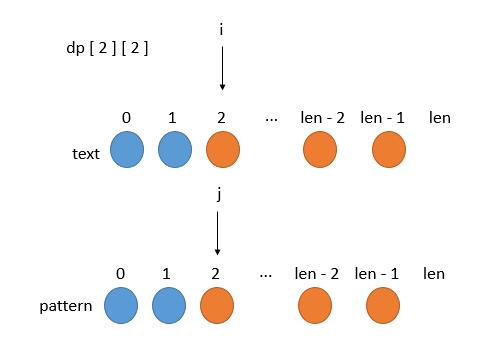
dp[2][2]就是图中橙色的部分.
public boolean isMatch(String text, String pattern) {
// 多一维的空间,因为求 dp[len - 1][j] 的时候需要知道 dp[len][j] 的情况,
// 多一维的话,就可以把 对 dp[len - 1][j] 也写进循环了
boolean[][] dp = new boolean[text.length() + 1][pattern.length() + 1];
// dp[len][len] 代表两个空串是否匹配了,"" 和 "" ,当然是 true 了。
dp[text.length()][pattern.length()] = true;
// 从 len 开始减少
for (int i = text.length(); i >= 0; i--) {
for (int j = pattern.length(); j >= 0; j--) {
// dp[text.length()][pattern.length()] 已经进行了初始化
if(i==text.length()&&j==pattern.length()) continue;
boolean first_match = (i < text.length() && j < pattern.length()
&& (pattern.charAt(j) == text.charAt(i) || pattern.charAt(j) == '.'));
if (j + 1 < pattern.length() && pattern.charAt(j + 1) == '*') {
dp[i][j] = dp[i][j + 2] || first_match && dp[i + 1][j];
} else {
dp[i][j] = first_match && dp[i + 1][j + 1];
}
}
}
return dp[0][0];
}
时间复杂度:假设 text 的长度是 T,pattern 的长度是 P ,空间复杂度就是 O(TP)。
空间复杂度:申请了 dp 空间,所以是 O(TP),因为每次循环我们只需要知道 i 和 i + 1 时候的情况,所以我们可以向 第 5 题 一样进行优化。
public boolean isMatch(String text, String pattern) {
// 多一维的空间,因为求 dp[len - 1][j] 的时候需要知道 dp[len][j] 的情况,
// 多一维的话,就可以把 对 dp[len - 1][j] 也写进循环了
boolean[][] dp = new boolean[2][pattern.length() + 1];
dp[text.length()%2][pattern.length()] = true;
// 从 len 开始减少
for (int i = text.length(); i >= 0; i--) {
for (int j = pattern.length(); j >= 0; j--) {
if(i==text.length()&&j==pattern.length()) continue;
boolean first_match = (i < text.length() && j < pattern.length()
&& (pattern.charAt(j) == text.charAt(i) || pattern.charAt(j) == '.'));
if (j + 1 < pattern.length() && pattern.charAt(j + 1) == '*') {
dp[i%2][j] = dp[i%2][j + 2] || first_match && dp[(i + 1)%2][j];
} else {
dp[i%2][j] = first_match && dp[(i + 1)%2][j + 1];
}
}
}
return dp[0][0];
}
时间复杂度:不变, O(TP)。
空间复杂度:主要用了两个数组进行轮换,O(P)。
总
这道题对于递归的解法,感觉难在怎么去求时间复杂度,现在还没有什么思路,以后再来补充吧。整体来说,只要理清思路,两种算法还是比较好理解的。
作者:windliang
来源:https://windliang.cc
看完两件小事
如果你觉得这篇文章对你挺有启发,我想请你帮我两个小忙:
- 把这篇文章分享给你的朋友 / 交流群,让更多的人看到,一起进步,一起成长!
- 关注公众号 「方志朋」,公众号后台回复「666」 免费领取我精心整理的进阶资源教程

本文著作权归作者所有,如若转载,请注明出处
转载请注明:文章转载自「 Java极客技术学习 」https://www.javajike.com
 微信扫一扫
微信扫一扫